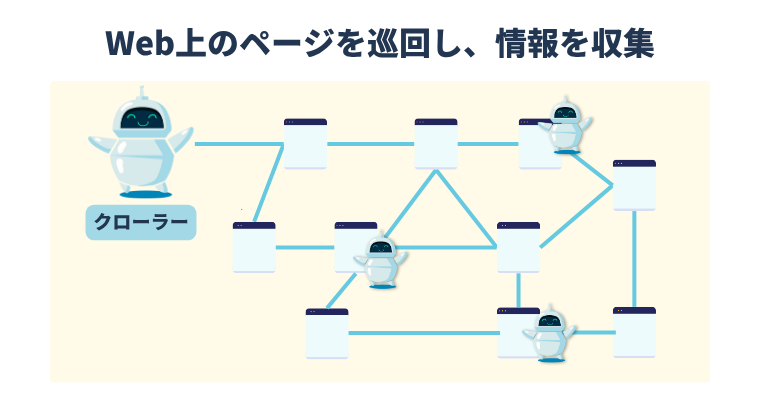
SEOを進める上で、まず理解しておきたいのが「クローラー」です。
クローラーとは、検索エンジンがWeb上のページを自動的に巡回し、情報を収集するプログラムのこと。
どれだけ質の高いコンテンツを作成しても、クローラーに正しくWebサイトを巡回してもらえなければ、検索結果に表示されることはありません。
ここでは、クローラーの基本的な仕組みや、巡回されやすいWebサイトの特徴などについて紹介します。
SEOの基礎知識 TOPページへSEOにお困りの方へ

本資料はSEOに必要な基本的な知識を理解し、最適な結果を得るために役立つ方法を詳細に説明しています。SEOに関連する問題に直面している方は、無料の相談サービスを利用することで、解決策を見つけることができます。ぜひ、今すぐお申し込みください!
目次
クローラーの役割と重要性
クローラーとは、インターネット上のWebページを自動的に巡回し、情報を収集するプログラムのことです。
検索エンジンのクローラーは、Web上に存在する膨大な数のページを探し出し、その内容を読み取って検索エンジンのデータベースに登録する役割を担っています。
私たちが日常的に利用しているGoogleやBingなどの検索エンジンは、このクローラーが収集した情報をもとに、次のような流れで検索順位を決定しています。
<検索エンジンが検索順位を決定するまでの流れ>
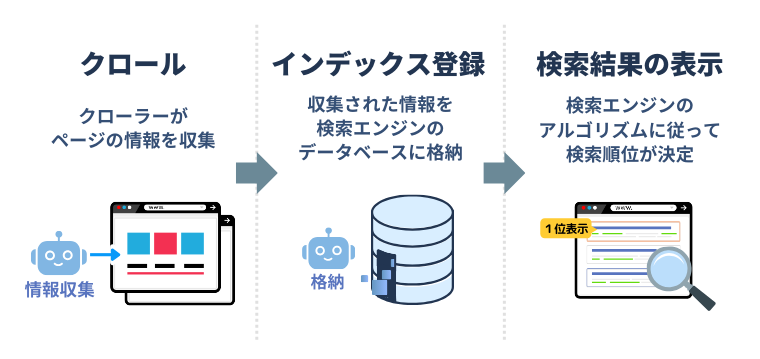
つまり、クローラーは検索エンジンの「目」となり、Web上の情報を発見・把握するために重要な存在なのです。
<クローラーが担う3つの主要な役割>
- 新しいページを見つける
クローラーは、既存のWebページからリンクをたどったり、サイトマップを参照したりすることで、新たに公開されたWebページを発見する。 - 既存ページの更新を確認する
古い情報から新しい情報へと内容が変わった際、クローラーが再び巡回することで変更が反映される。 - 検索結果に反映させるための情報を集める
クローラーが収集したWebページのテキストや画像、リンク構造などの情報は、検索エンジンのアルゴリズムによって分析され、順位を決定する判断材料となる。
クローラーがWebページを巡回しなければ、どんなに質の高い記事を書いても検索結果には表示されません。
言い換えれば、クローラーに正しく巡回してもらうことが、SEOの第一歩となるのです。
詳しくはこの記事もチェック!


クローラーの種類
クローラーは検索エンジンごとに異なるプログラムが用意されており、それぞれ固有の名称を持っています。代表的なクローラーをいくつか紹介します。
<クローラーの代表的な種類>
- Googlebot
Googleが使用するクローラーで、世界で最も広く利用されている検索エンジンであるGoogleの検索結果を支えている。
デスクトップ版とモバイル版があり、現在はモバイル版のクローラーを基準にインデックスが行われる「モバイルファーストインデックス」が主流。 - Bingbot
Microsoftが提供する検索エンジン「Bing」のクローラー。
Googleに次ぐシェアを持ち、特に一部の国や地域では重要な検索エンジンとして利用されている。
そのほかにも、Baiduspider(中国)、YandexBot(ロシア)など、各国の検索エンジンがそれぞれ独自のクローラーを運用しています。
また、近年ではChatGPTをはじめとしたAIサービスが情報収集や分析をするためのクローラーも増えてきています。
クローラーが巡回しやすいWebサイトの特徴
クローラーが正しく巡回できるかどうかを、「クローラビリティ」と呼びます。
クローラビリティが高いWebサイトとは、クローラーがスムーズにページを発見し、情報を収集できる状態が整っているサイトのこと。
クローラビリティが低いと、新しく公開したページがなかなか検索結果に反映されなかったり、既存ページの更新内容が検索エンジンに認識されにくくなったりします。
その結果、SEO施策の効果が十分に発揮されない可能性があるため、クローラビリティを高めることはSEOの基本的な取り組みとして重要です。
ここでは、クローラーが巡回しやすいWebサイトに共通する特徴を見ていきましょう。
<クローラーが巡回しやすいWebサイトの特徴>
内部リンクが整理されている
クローラーは、すでに発見しているページからリンクをたどり、新しいページを見つけていきます。
そのため、Webサイト内の重要なページに適切に内部リンクが貼られているかどうかが、クローラビリティに大きく影響するのです。
例えば、トップページから主要なカテゴリページへリンクが貼られ、そこから各記事ページへとリンクがつながっていれば、クローラーはWebサイト内をスムーズに巡回できます。
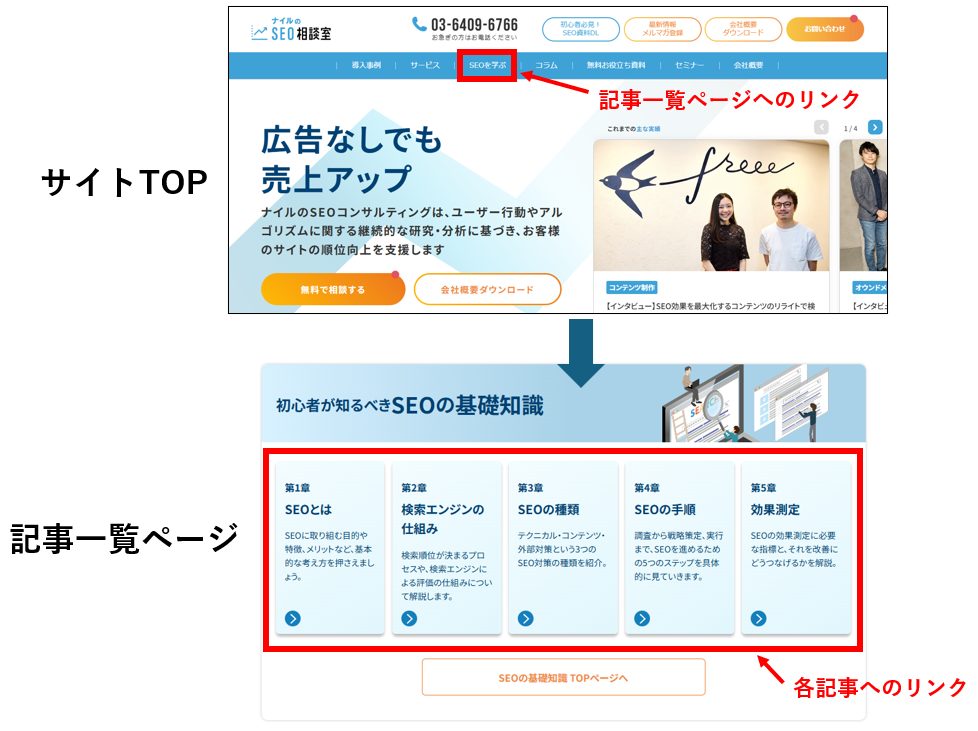
一方で、どのページからもリンクされていない「孤立したページ」は、クローラーに発見されにくくなってしまいます。
また、重要なページほどWebサイト内の多くのページからリンクされている状態が理想的。
内部リンクの数や配置は、そのページの重要度をクローラーに伝える役割も果たすからです。
内部リンクを整理する際は、ユーザーにとって自然でわかりやすいナビゲーションを意識しながら、重要なページへの導線を確保することを心がけましょう。
詳しくはこの記事もチェック!

ページ表示速度が速い
ページの読み込み速度は、クローラビリティにも影響を与えます。
表示速度が遅いページは、クローラーが情報を収集するのに時間がかかるため、限られた時間内で巡回できるページ数が減ってしまう可能性があります。
特に大規模なサイトでは、1ページあたりの読み込み時間が数秒違うだけで、全体のクロール効率に大きな差が生まれるので、意識したいたいところ。
画像の最適化、不要なスクリプトの削除、サーバーのレスポンス速度の改善など、ページ速度を向上させる取り組みは、ユーザー体験の向上だけでなく、クローラビリティの改善にもつながります。
GoogleのPageSpeed Insightsなどのツールを活用して、自サイトのページ表示速度を定期的にチェックし、改善できる点がないか確認してみましょう。
詳しくはこの記事もチェック!

XMLサイトマップから読み込む
XMLサイトマップは、Webサイト内の重要なページのURLをリスト化したファイルのこと。
Google Search Consoleなどで検索エンジンに送信することで、クローラーに「このWebサイトにはこれらのページが存在しますよ」と直接伝えることができます。
ただし、XMLサイトマップは、ページ数が少なく、内部リンクがしっかり整備されている中小規模のサイトであれば、基本的には不要。
クローラーはリンクをたどるだけで十分にサイト内を巡回することが可能だからです。
一方で、数千ページを超える大規模サイトや、リンク構造が複雑なWebサイトの場合は、クロールの抜け漏れを防ぐためにXMLサイトマップが重要になります。
自サイトの規模や構造に応じて必要性を判断しましょう。
クロールバジェットとは
検索エンジンのクローラーは、無制限にWebサイトを巡回できるわけではありません。
ひとつのWebサイトに割けるクロールのリソースには限りがあり、その上限量を「クロールバジェット」と呼びます。
クロールバジェットは、サーバーへの負荷やクローラー自体のリソースを考慮して、各サイトに割り当てられているもの。
そのため、Webサイトが大規模になるほど、すべてのページを十分にクロールしきれず、重要なページがクロールされないリスクが高まります。
中小規模のWebサイトであれば、気にする必要はほとんどありません。
しかし、数千〜数万ページを超える大規模サイトでは、クロールバジェットを無駄遣いしないための工夫が必要です。
大規模サイトを運営している場合は、次のクロールバジェットの無駄遣い例を参考に、効率的にクロールできるようになっているかを確認しましょう。
<クロールバジェットの無駄遣い例と対策>
- 同じ内容のページがURLパラメータ違いで大量に存在
例えば、「?sort=price」や「?color=red」のようなURLパラメータによって、同じ商品一覧ページが複数のURLで生成されている場合、クローラーは実質的に同じページを何度も巡回してしまう。
対策:URLパラメータの整理や、canonicalタグで代表URLを指定する。 - 色やサイズなど商品バリエーションごとに個別ページが生成されている
ECサイトなどで、「赤いTシャツ」「青いTシャツ」など、バリエーションごとに別々のページが自動生成されていると、重複に近いページが大量に発生する。
対策:代表となる商品ページにcanonicalタグを設定するか、不要なバリエーションページにnoindexを設定する。 - 古くて不要なページ(テスト用・アーカイブ)が放置されている
過去のキャンペーンページやテスト用ページなど、もう価値のないページが残っていると、クローラーはそれらも巡回してしまう。
対策:不要なページを削除するか、noindexを付与する(※)。
※ただし、noindexを設定してもクロールの頻度が下がるだけで、完全にクロール対象から外れるわけではない。 - 内部リンク構造が不適切で「重要でないページ」ばかり巡回してしまう
Webサイト内のリンク構造が整理されていないと、クローラーは重要度の低いページに多くの時間を使ってしまう可能性がある。
対策:内部リンクを整理し、重要なページへの導線を優先的に設計する。
なお、Googleでは大規模サイトの所有者に向けた、クロールバジェットの管理ガイドを公開しているので、こちらも参考にしてください。
大規模サイトのクロール バジェット管理 - Google 検索セントラル
詳しくはこの記事もチェック!



よくあるクローラー関連の疑問
クローラーについて理解を深めていくと、実際の運用面でさまざまな疑問が生まれてくるかもしれません。
ここでは、よくあるクローラーにまつわる疑問に答えていきます。
クローラーはどのくらいの頻度で来る?
Googleではクロールの頻度について、次のように発表しています。
Google クローラーのインフラストラクチャでは、高度なアルゴリズムで各サイトに最適なクロール頻度が決定されています。
クローラーの巡回頻度はWebサイトによって異なるほか、システム障害などの緊急時は巡回頻度を下げることも可能です。
新規サイトにクローラーが来ない場合の対処法
新しくWebサイトを立ち上げた直後は、検索エンジンがまだそのサイトの存在を認識していないため、クローラーがなかなか訪れないことがあります。
そこで、新規サイトにクローラーを呼び込むための対処法をいくつか紹介しましょう。
<クローラーを呼び込むための対処法>
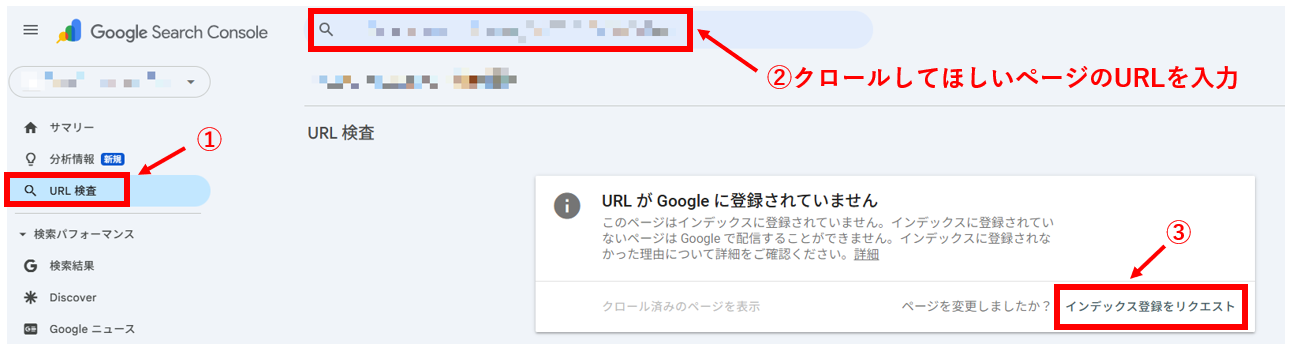
Google Search Consoleでインデックス登録をリクエスト
Google Search Consoleにサイトを登録し、URL検査機能を使って重要なページのクロールを直接リクエストできます。
トップページや重要なページは、この方法で早めに認識させるといいでしょう。
既存のサイトからリンクを獲得する
ほかのWebサイトからリンクが貼られていると、クローラーがリンクをたどって新規サイトを発見しやすくなります。
プレスリリースやSNSでの拡散、自社関連サイトからのリンク設置などが有効です。
SNSや外部サービスでWebサイトのURLをシェアする
X(旧Twitter)やFacebook、ブログサービスなどでWebサイトのURLをシェアすることも効果的です。
Googlebotは直接SNSのリンクをたどることは少ないですが、外部からのアクセスが増えるとクロール対象として認識されやすくなります。
クローラーがサーバーに負荷をかけることはある?
中小規模のサイトであれば、クローラーによるサーバー負荷を心配する必要はほとんどありません。
Googlebotをはじめとする主要な検索エンジンのクローラーは、サーバーに過度な負担をかけないよう設計されており、適切な間隔でページを巡回します。
ただ、昨今は生成AIの普及によって、状況が少し変わってきています。
ChatGPTをはじめとする生成AIサービスの学習データ収集や、さまざまな新興AI企業が独自に運用するクローラー(AI bot)が急増しており、サイト規模を問わず、これらのAI botが短期間に大量のページをクロールしてサーバー負荷をかけるケースが問題になっています。
もしサーバーのアクセスログで原因不明の大量のクロールが確認された場合は、robots.txtファイルで特定のクローラーのアクセスを制限するなどの対策を検討しましょう。
ただし、Googlebotなど主要な検索エンジンのクローラーはブロックしないよう注意が必要です。
クローラーを理解し、巡回されやすいWebサイトを目指そう
検索エンジンのクローラーは、ページを発見・記録し、検索結果に反映させる重要な役割を担っています。
クロール→インデックス→ランキングの流れを踏まえ、クローラビリティを高めることがSEOの第一歩。
内部リンクやページ表示速度の最適化といった基本対策は欠かせません。
クローラーへの理解を深め、適切な対策を講じることで、検索上位を目指すための基盤を作りましょう。
SEOの基礎知識 TOPページへSEO対策の悩みをプロに相談してみませんか?

SEOやWebマーケティングの悩みがありましたら、お気軽にナイルの無料相談をご利用ください!資料では、ナイルのSEO支援実績(事例)、コンサルティングの方針や進め方、費用の目安といった情報をご紹介しています。あわせてご覧ください。



編集者
一般情報誌や音楽情報メディアの編集部を経て、2017年にナイルへ入社。コンテンツディレクターとして主に医療系、ライフスタイル系などさまざまなメディアで顧客支援を行う。現在は主に「ナイルのSEO相談室」の制作を担当。
SEO基礎知識 記事一覧
-
- LLMOの効果測定
- LLMO
- AI Overviews
- LLMマーケティング
- ローカルSEO
- Googleコアアップデート
- 構造化データ
- YMYL
- 強調スニペット
- ナレッジパネル
- リッチスニペット
- 内部リンク
全部みる 閉じる

-
全部みる 閉じる
-
- サブドメインとサブディレクトリ
- エンティティ
- コアウェブバイタル
- サイテーション
- SEO記事の作り方
- 検索ボリューム
- ディレクトリ
- リダイレクト
- ペルソナ
- 指名検索
- noindex
- nofollow
- HTTPS
- 被リンク
- 重複コンテンツ
- CMS
- canonical
- URLパラメータ
- URL正規化
- alt属性
- robot.txt
- クリック率
- コンバージョン
- Googleサーチコンソール
- アンカーテキスト
全部みる 閉じる
-
全部みる 閉じる
-
全部みる 閉じる