


robots.txt(ロボット テキスト)とは、検索エンジンのクローラーに、Webサイト内で巡回を許可、あるいは拒否する箇所を伝えるためのテキストファイル。
SEOにおいては、適切なインデックスを促すために欠かせないツールのひとつです。
本記事では、robots.txtの基本的な仕組みやSEOへの影響、正しい記述方法、注意したいポイントなどを詳しく解説します。
SEOの基礎知識 TOPページへ新任担当者がSEOの落とし穴にハマらないために

これからSEOに取り組む新任担当者向けにSEOの基礎知識をまとめました。本資料では、やってはいけないNG施策、マーケティングから見たSEOなどを解説しています。後半ではSEO業務におけるChatGPTの活用法もご紹介しているので、興味のある方はお気軽にお申し込みください。
目次
robots.txtの役割
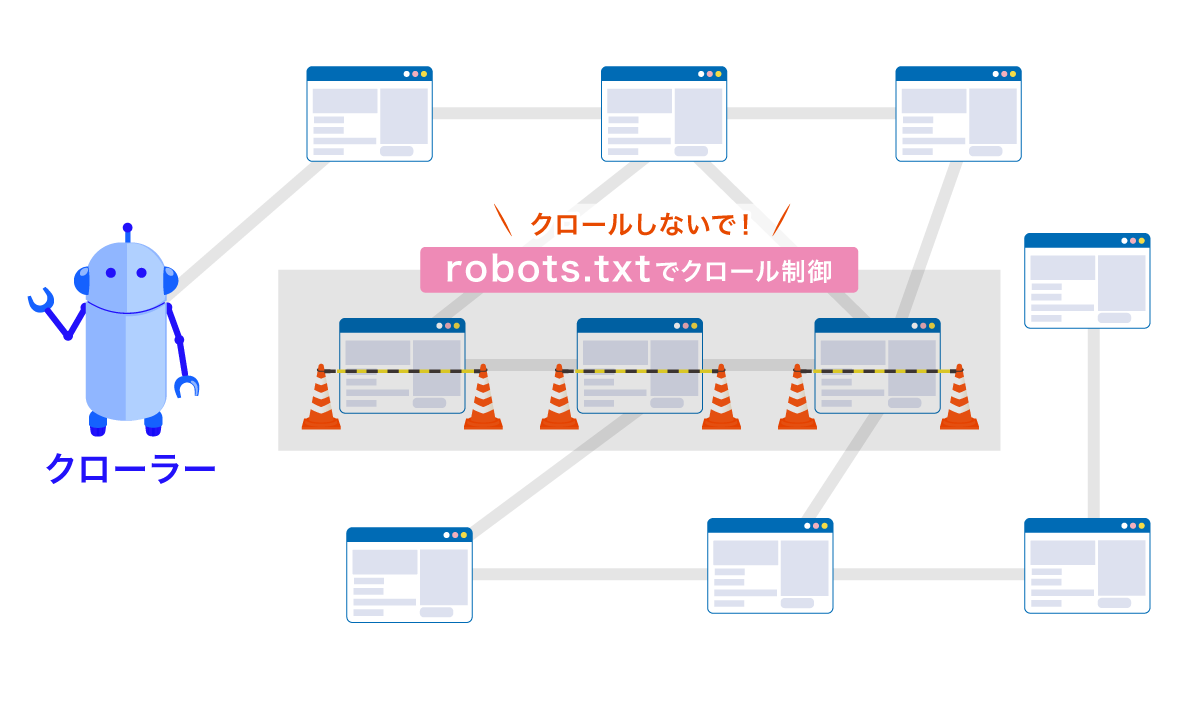
robots.txt(読み方は「ロボット テキスト」が一般的)とは、検索エンジンのクローラーに「どのページやディレクトリにアクセスしてほしくないか」を伝えるためのテキストファイルです。
robots.txtを使えば、クロールされる必要のないページ――開発中のテストページ、管理画面へのログインページ、PDFファイルが大量に格納されたディレクトリなど――へのクローラーのアクセスを制御できます。
ただし、robots.txtでクロールを制御したからといって、必ずしも検索結果に表示されないわけではありません。
外部サイトからリンクが貼られている場合など、URL自体が知られていれば、クローラーがページ内容を取得しなくても検索結果に表示されることがあります。
詳しくはこの記事をチェック!


robots.txtを設置する目的
robots.txtを設置する目的は、大きく分けて「SEO観点での目的」と「Webサイトの運営・管理上の目的」の2つがあります。
<robots.txtを設置する目的>
SEO観点での目的
SEOの視点から見ると、robots.txtは検索エンジンのクローラーを効率的に誘導するための重要なツールです。
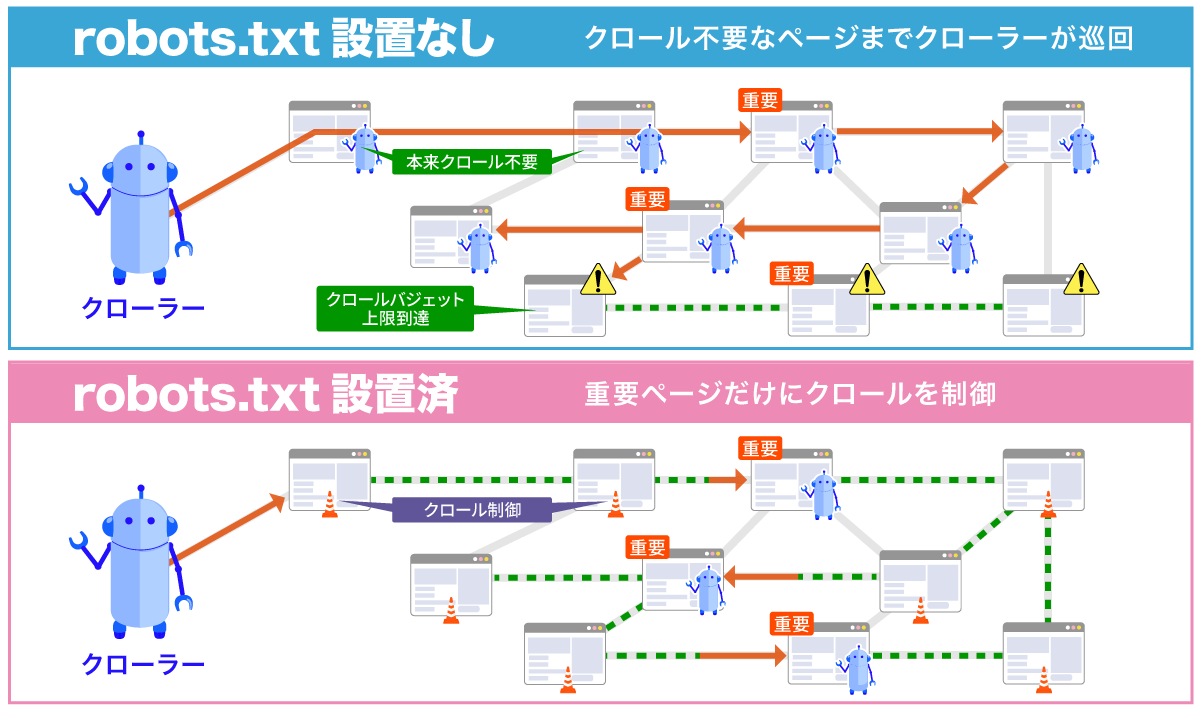
検索エンジンのクローラーは、1つのWebサイトに割り当てられたクロールバジェット(クロールの上限回数)の範囲内でページを巡回します。
そのため、クロールが不要なページ(重複コンテンツ)やサイト内検索結果ページなど)が大量に生まれやすい大規模サイトの場合は、重要なページにクローラーが確実に巡回できるような制御が必要です。
そこで、robots.txtを使って不要なページのクロールを制限すれば、限られたクロールバジェットを有効活用でき、重要なページをより早く・頻繁にクロールしてもらえるようになります。
結果として、適切なインデックス登録を促し、SEO評価の安定につながるのです。
Webサイトの運営・管理上の目的
robots.txtは、SEOだけでなくサイト運用の安定性にも役立ちます。
検索エンジンのクローラーは、短時間に大量のページへアクセスすることがあります。
特に大規模サイトや、動的に生成されるページが多いWebサイトでは、クローラーの巡回がサーバーに大きな負荷をかけることがあるため、注意が必要です。
そこで、robots.txtでクロール対象を制御すれば、特定のディレクトリや一時的な作業用ページへのアクセスを制限でき、サーバー負荷の軽減につながります。
さらに、特定のクローラーだけを制御したい場合にも、robots.txtは有効。
例えば、自社コンテンツをAIの学習データに使われたくない場合は、ChatGPTなどのAI学習用クローラーだけをブロックしたり、画像検索エンジンのクローラーのみを制限したりといった、細かな制御も可能です。
robots.txtの記述方法
robots.txtの基本的な記述方法について、具体例を交えながら紹介しましょう。
robots.txtは、Webサイトのルートディレクトリ(トップページと同じ階層)に配置する必要があります。
サブドメインへ設置することもできますが、サブディレクトリ内に設置するとクローラーは認識しないため、必ずルートに1つだけ設置しましょう。
例1:https://example.com/robots.txt
例2:https://sub.example.com/robots.txt
robots.txtを記述する際は、
という3つの要素を組み合わせて行います。
どのロボットが(User-agent)
「User-agent」は、制御対象となる検索エンジンのクローラーを指定するための記述です。
クローラーごとに異なる名前が設定されており、この名前を使って特定のクローラーに対するルールを定義します。
最も基本的な指定方法は、アスタリスク(*)を使った記述です。
「User-agent: *」と記述すると、すべてのクローラーに対してルールが適用されます。
特定の検索エンジンのクローラーだけを制御したい場合は、そのクローラー名を指定しましょう。
例えば、「User-agent: Googlebot」と記述すればGoogleのクローラーのみ、「User-agent: Bingbot」であればBingのクローラーのみに対するルールになります。
どのページ/ディレクトリ/ファイルに(URLパス)
制御対象となるページやディレクトリ、ファイルの場所を、URLのパス(ドメイン以降の部分)で指定します。
この指定方法によって、Webサイト全体、特定のディレクトリ、個別のファイルなど、さまざまな範囲でクロール制御ができます。
<範囲を指定する場合の記述例>
/private/
ディレクトリ全体を指定する場合は、最後にスラッシュ(/)を付けます。
上記の場合は、「private」ディレクトリ以下のすべてのページが対象です。/test.html
特定のファイルを指定する場合は、ファイル名まで含めたパスを記述します。
上記の場合は、「test.html」ファイルだけが対象です。/*.pdf
「*」を使うことで、より柔軟な指定が可能。
上記のように記述すると、すべてのPDFファイルを対象にできます。
クロールしても良い/クロールしてはいけない(Allow/Disallow)
「Allow」(許可)と「Disallow」(禁止)を使って、指定したパスに対してクロールを許可するか禁止するかを設定します。
この2つのディレクティブを組み合わせることで、細かなアクセス制御が可能です。
<全ページをクロール許可する場合>
User-agent: * Disallow:
すべてのクローラーに対して、Webサイト全体のクロールを許可する場合の記述です。
これはrobots.txtを設置しない場合と同じ状態ですが、明示的に許可を示したい場合に使用します。
<全ページをクロール禁止にする場合>
User-agent: * Disallow: /
「Disallow: /」と記述することで、ルートディレクトリ以下のすべてのページ(つまりWebサイト全体)へのクロールが禁止されます。
<一部だけ禁止にする場合>
User-agent: * Disallow: /private/ Disallow: /test.html
特定のディレクトリやページだけをクロール禁止にする、最も実用的な記述パターンです。
この例では、privateディレクトリ、test.htmlファイルへのクロールが禁止され、それ以外のページは自由にクロールできます。
<禁止と許可を組み合わせる場合>
User-agent: * Disallow: /private/ Allow: /private/public/
AllowとDisallowを組み合わせることで、より細かな制御も可能。
この例では、privateディレクトリ全体を禁止しつつ、その中のpublicディレクトリだけは例外的に許可しています。
追加情報:Sitemapの指定
robots.txtには、XMLサイトマップのURLを記載することもできます。
これは必須ではありませんが、XMLサイトマップを記載しておくことで、検索エンジンに効率良くWebサイト全体の構造を伝えることが可能です。
<Sitemapを指定する場合>
User-agent: * Disallow: /admin/
Sitemap: https://example.com/sitemap.xml
Sitemapの記述は、User-agentやDisallowの記述の後に、独立した行として追加します。
複数のサイトマップがある場合は、それぞれ別の行に記述することも可能です。
robots.txtの確認方法
robots.txtを作成・設置したら、正しく動作しているかを確認することが重要です。
記述ミスがあると、意図しないページがクロール禁止になってしまったり、逆に禁止したいページがクロールされてしまったりする可能性があります。
<robots.txtの確認方法>
テストツールでの確認
テストツールは、本番環境で設置する前に、「想定した範囲が適切にブロックされているか」を確認するために利用するのが一般的です。
そこでおすすめのツールは、「robots.txt Validator and Testing Tool」です。
これを使って、DisallowにしたいURLが記述ルールに含まれているかを確認する方法を解説しましょう。
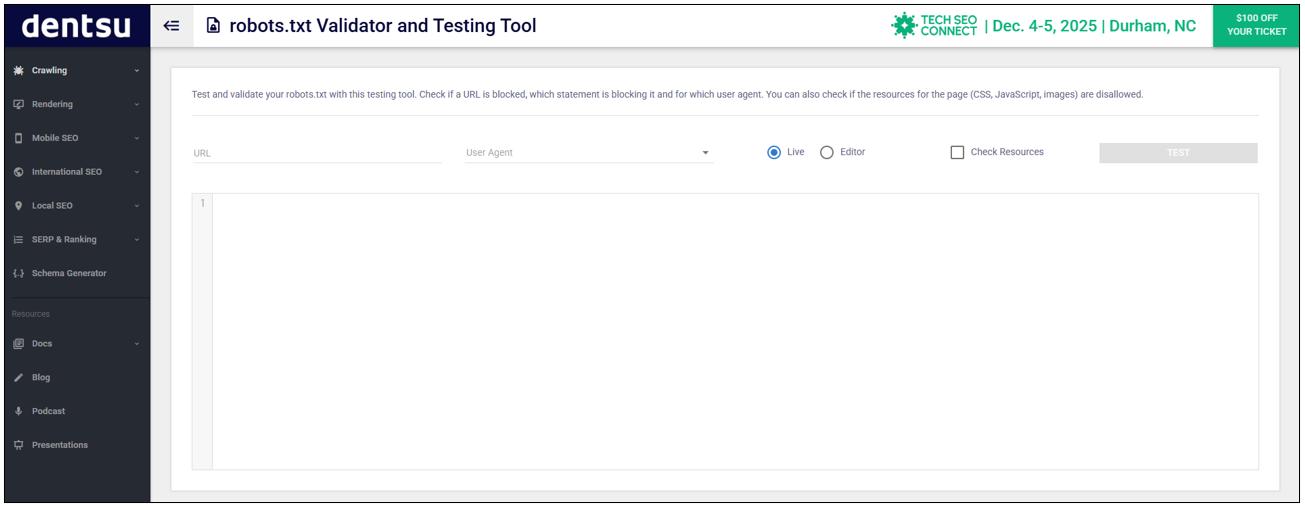
<robots.txt Validator and Testing Toolでの確認手順>
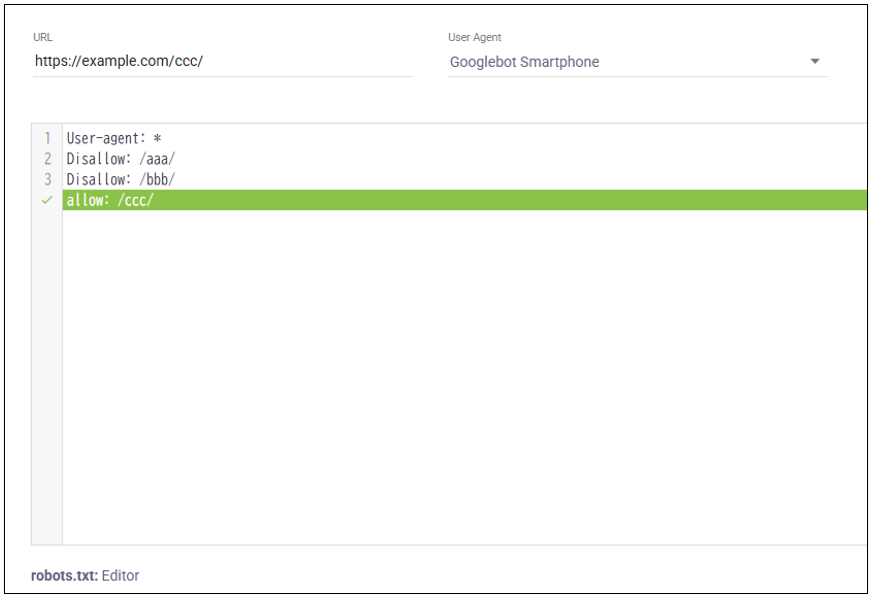
- URLの欄にテストしたいURLを入力
- User Agentに制御対象とする検索エンジンのクローラーを指定
- 下の枠内にrobots.txtに記述するテキストを入力し、TESTをクリックする
すると、Disallowルールが適用されている(クロールがブロックされている)行は赤く表示されます。
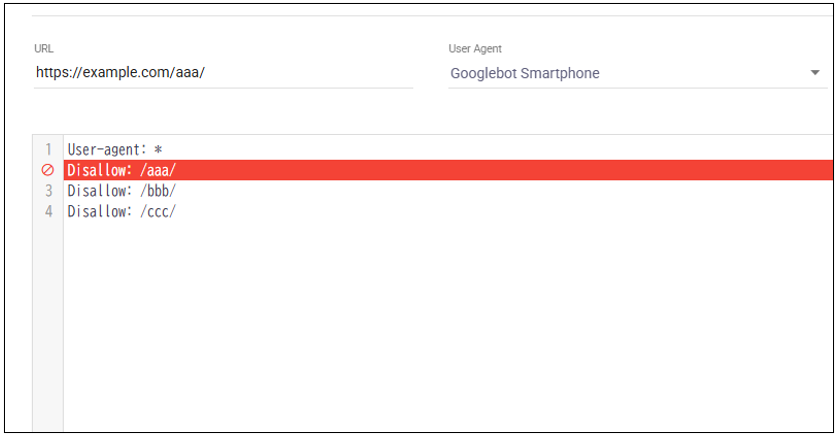
逆に、Disallowしたくない(つまいallowにしたい)URLを入れ、どこも赤くならない(緑で表示される)ことを確認する方法もあります。
Google Search Consoleでの確認
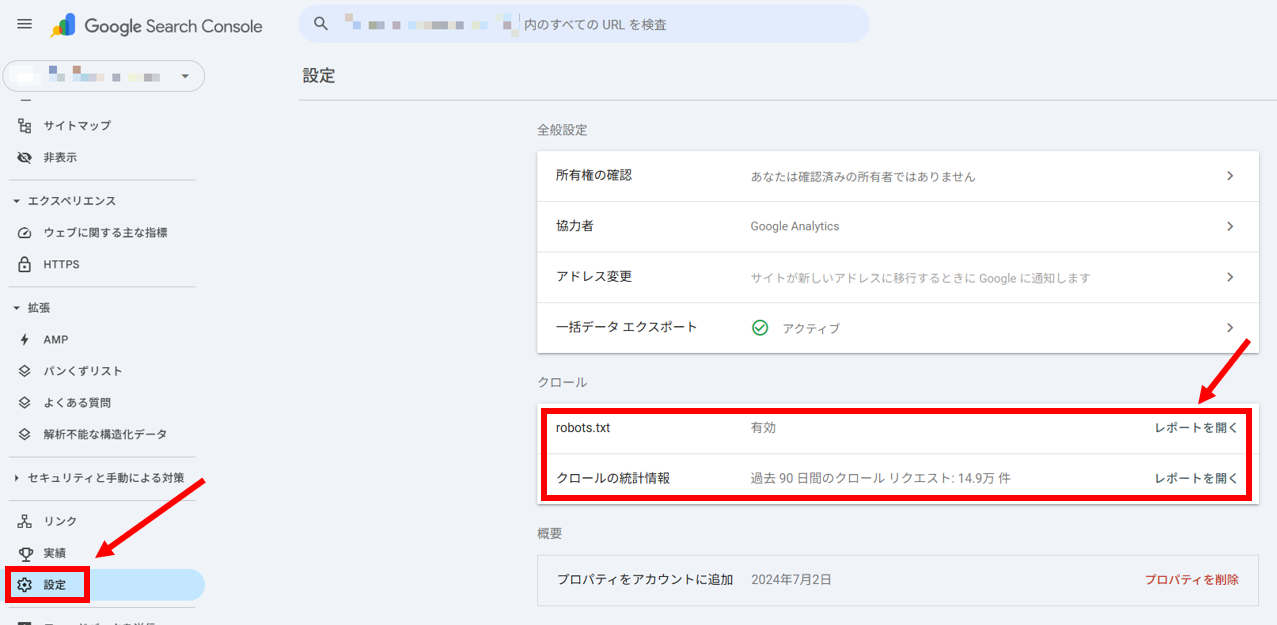
本番環境では、Google Search Consoleのrobots.txtレポートで確認します。
- Google Search Consoleのメニュー「設定」→「クロール」内「robots.txt」から「レポートを開く」をクリック。
- ステータスが「取得済み」となっていれば、robots.txtファイルを正しく設定できています。
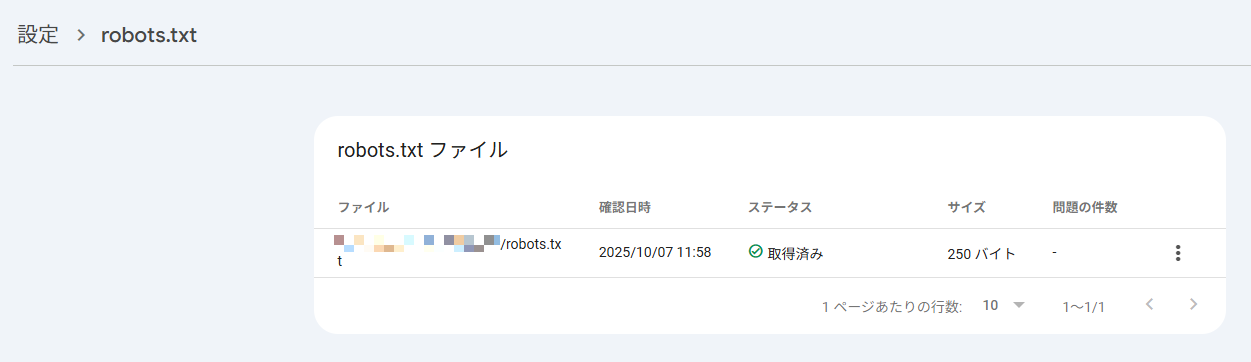
なお、「取得済み」以外のステータスになっていた場合は、次のような意味です。
<ステータスの表示と意味>
| 表示 | 意味 |
|---|---|
| 取得できませんでした | Google がファイルにアクセスできない状態
URLやサーバー設定を要確認 |
| パースエラー | 記述に誤りがあり、一部のルールが無効化されている可能性
構文を要確認 |
クロールの除外理由も確認可能
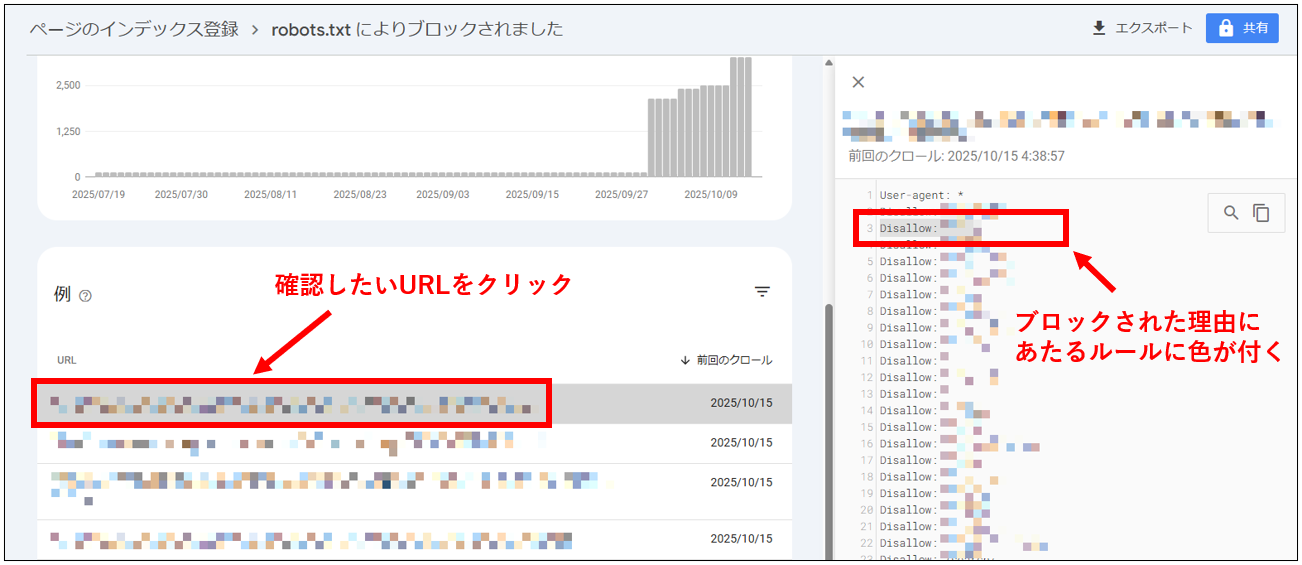
Google Search Consoleでは、どのルールでクロールが除外されたかも確認が可能です。
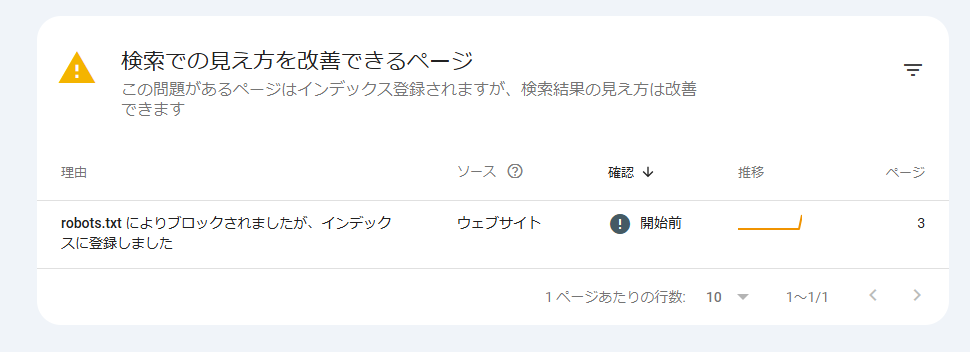
左メニュー「ページ」→「ページがインデックスに登録されなかった理由」欄の「robots.txtによりブロックされました」をクリックすると、下掲画像の表示になります。
そこで確認したいURLをクリックすると、右枠にブロックの理由となっているルールが表示されます。
robots.txtのよくある誤解と注意点
robots.txtはSEOやサイト運用の基本的な設定のひとつですが、役割を誤解しているケースも少なくありません。
ここでは、特に初心者が混同しやすいポイントや、設定時に注意したい点を整理します。
<robots.txtのよくある誤解と注意点>
robots.txtの設置は必須ではない
まず前提として、robots.txtはすべてのサイトに必ずしも必要ではありません。
ECサイトやニュースメディアなど、数千〜数万ページにおよぶ大規模サイトを除き、小中規模のサイトではクロールを細かく制御する必要がない場合がほとんどです。
検索エンジンはデフォルトで全ページをクロール対象とするため、特に制限をかける意図がなければ、robots.txtを無理に設置しなくても問題ありません。
ただ、大規模サイトの場合は、不要な領域(検索結果ページ、システムディレクトリなど)を除外することでクロール効率を高める効果があります。
つまり、robots.txtはWebサイトの規模や構造に応じて必要性を判断するものと考えましょう。
robots.txtでインデックスを完全に防ぐことはできない
robots.txtはクロール(ページの読み取り)を制御する仕組みであり、インデックス登録自体を完全に防ぐものではありません。
例えば、外部サイトからリンクが貼られている場合、robots.txtでクロールを禁止していても、そのURLが「リンク先として存在する」として検索結果に表示される可能性があります。
<robots.txtを設置していてもインデックスされている例>
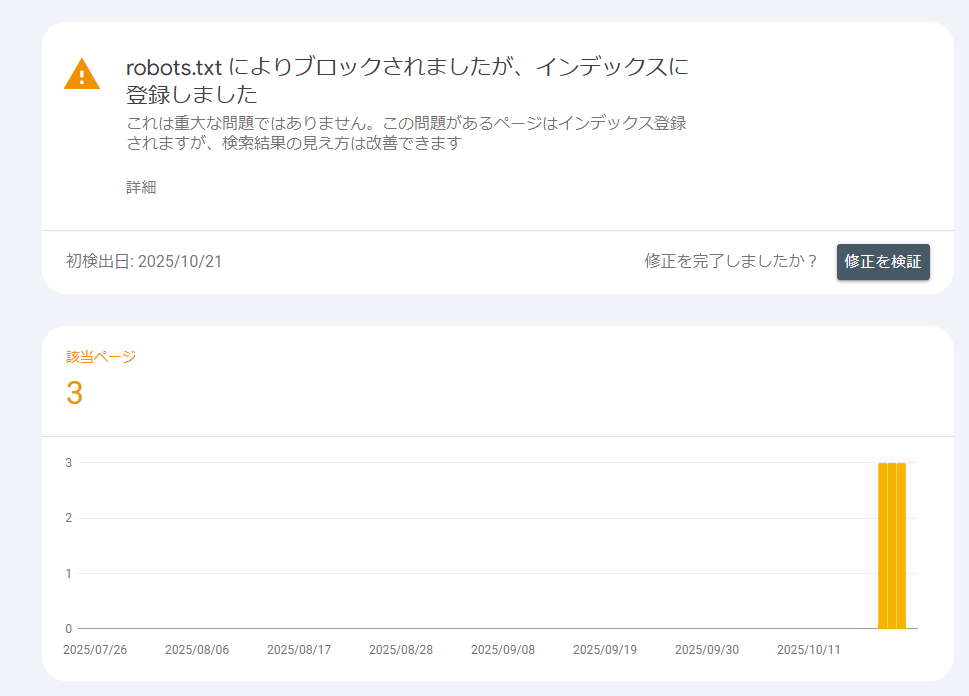
そのため、確実にインデックスさせたくない場合は、noindexを指定しましょう。
noindexとの使い分けについては、次の項目で詳しく解説します。
noindexとの使い分け
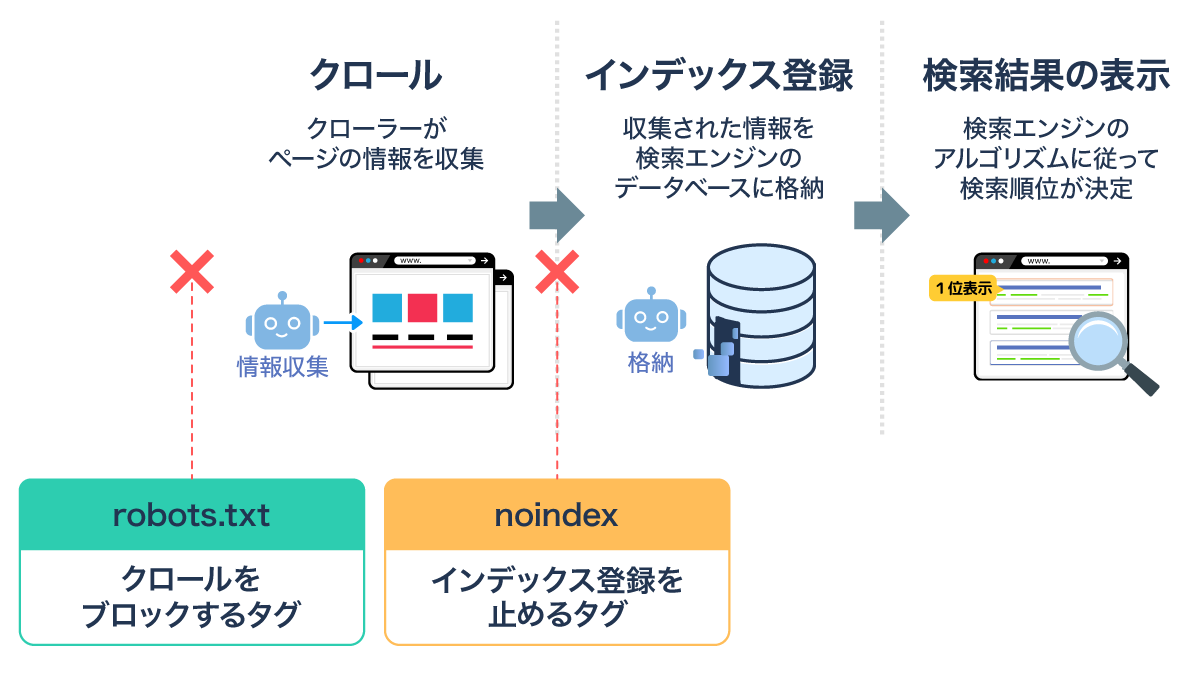
robots.txtとnoindexは、「クロールの制御」と「インデックスの制御」という点で役割が異なります。
<robots.txtとnoindexの役割の違い>
| 制御方法 | 主な目的 | 有効なタイミング |
|---|---|---|
| robots.txt | クローラーのページへのアクセスを制御 | クロール前(アクセス前) |
| noindex | ページを検索結果に表示させない | クロール後(ページ内容を取得した上で) |
そのため、検索結果に出したくないページはnoindexを使うのが原則。
逆に、管理画面などそもそもクロールさせたくない領域では、robots.txtが適しています。
両者を混同すると、意図しない非表示・検索結果への表示漏れを招くことがあるため、明確に使い分けましょう。
設定ミスでWebサイト全体が非公開になるリスクがある
robots.txtの記述はシンプルですが、一文字のミスでサイト全体が非公開になる危険があります。
例えば、次のように「Disallow: /」とだけ記述すると、全ページのクロールを禁止してしまいます。
User-agent: * Disallow: /
これを本番環境に誤ってアップロードすると、Googleが一切のページをクロールできず、検索結果から全ページが消えてしまう(非公開状態になる)おそれがあるのです。
実際、開発環境からの移行時にこのミスが発生するケースは少なくありません。
修正しても再クロールまでには数日〜数週間かかる場合があるため、公開前には必ずテストツールで確認し、想定した範囲のみがブロックされていることをチェックしてから反映しましょう。
また、公開後はGoogle Search Consoleでファイルの状態を確認してください。
詳しくは、「robots.txtの確認方法」をご覧ください。
robots.txtは「クローラーへの道案内」
robots.txtは、検索エンジンのクロールを制御し、効率的な巡回を促すためのファイルです。
ただし、すべてのWebサイトに必ず必要なわけではなく、ページ数が多い大規模サイトで主に活用するものであることを理解しましょう。
また、設定ミスがあると、検索結果に表示されるべき重要ページの露出がなくなるおそれもあるため、robots.txtが正しく設置されているか、公開前後の確認を欠かさないことが大切です。
この記事を参考にrobots.txtを正しく理解し、効果的なWebサイト運営に役立てていきましょう。
SEOの基礎知識 TOPページへSEO対策の悩みをプロに相談してみませんか?

SEOやWebマーケティングの悩みがありましたら、お気軽にナイルの無料相談をご利用ください!資料では、ナイルのSEO支援実績(事例)、コンサルティングの方針や進め方、費用の目安といった情報をご紹介しています。あわせてご覧ください。



編集者
一般情報誌や音楽情報メディアの編集部を経て、2017年にナイルへ入社。コンテンツディレクターとして主に医療系、ライフスタイル系などさまざまなメディアで顧客支援を行う。現在は主に「ナイルのSEO相談室」の制作を担当。
SEO基礎知識 記事一覧
-
- LLMOの効果測定
- LLMO
- AI Overviews
- LLMマーケティング
- ローカルSEO
- Googleコアアップデート
- 構造化データ
- YMYL
- 強調スニペット
- ナレッジパネル
- リッチスニペット
- 内部リンク
全部みる 閉じる

-
全部みる 閉じる
-
- サブドメインとサブディレクトリ
- エンティティ
- コアウェブバイタル
- サイテーション
- SEO記事の作り方
- 検索ボリューム
- ディレクトリ
- リダイレクト
- ペルソナ
- 指名検索
- noindex
- nofollow
- HTTPS
- 被リンク
- 重複コンテンツ
- CMS
- canonical
- URLパラメータ
- URL正規化
- alt属性
- robot.txt
- クリック率
- コンバージョン
- Googleサーチコンソール
- アンカーテキスト
全部みる 閉じる
-
全部みる 閉じる
-
全部みる 閉じる











