※本記事は、2014年に執筆した記事です。
主に制作とか開発の仕事をされている方と話していて、URL正規化についての考え方、についてちょっと違うんじゃないのと思うことがたまにあるので書きます。すごく基本的なことなのですが、あまり話題として触れられていないように思ったので。
\SEO初心者向け!canonicalを解説した無料の資料はこちら/
目次
URLの正規化とは何ぞ、という方にまず解説
検索すればそういう記事はとてもたくさん出てきますが、サッパリでピンと来ませんという人のために、かなり粗いんですけど例えを入れておきますね。まずはイメージから。
例えばSalesforceみたいな基幹システムを色んな人が好き勝手触ってると、いつの間にかどんどんデータが乱れてくることってありますよね。その中でも結構やっかいなのがこういうデータの重複登録問題。
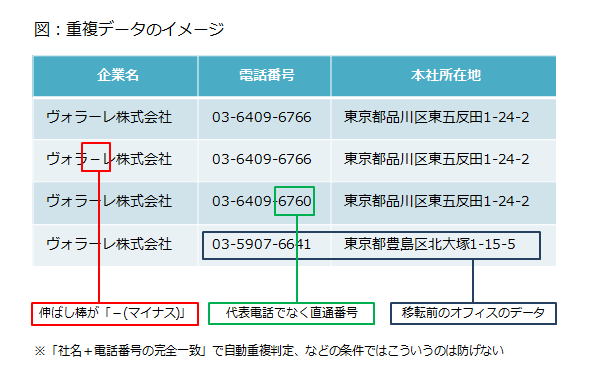
例えばですが、こういう感じですね。こうなってしまうと企業データを検索して新しいデータ入力しようとしたりするときに無駄な確認とか処理が発生しますよね。もちろんトラブルの原因にもなるのでこれはよろしくないです。
で、こういう風に「複数存在してしまっているけど実質同じものはひとつにまとめた方が良いよね」というのがいわゆるSEOの正規化のイメージです。
(補足)
もともと正規化って「”名寄せ”みたいな感じ」って言ったほうが近いものがあるかもしれませんが、SEOの話題としては必ずしも名寄せとは感覚が同じでない場合とかもあるのでそういうことにしておきます。
どっちにしても「1つであるべきデータがバラバラになっていたら管理とか処理にあたって色々不都合ありますよね」ということだと思っていて下さい。
SEOでいうところの正規化について
SEOでいうところの正規化のイメージは、「複数の異なるURLに同じコンテンツが存在する場合、どのURLを検索エンジンが評価すれば良いのかを1つ定めてそこに評価をまとめる」ということです。
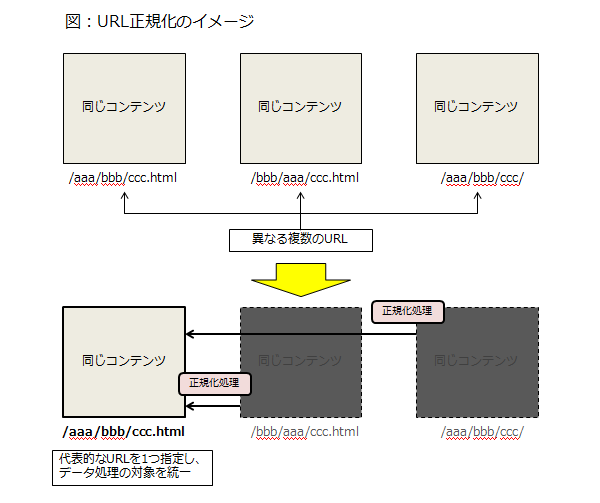
検索エンジンも、同じコンテンツなのに別々のURLでそれが返されてしまうと、「どれを見ればいいんだろ?」ということになって正しい処理が行われなかったり、少なくとも無駄な処理をさせることにはなってしまうわけですね。
規模や内容によりますが、あまりにこうした問題がサイト全体で好き勝手に発生しまくっているという状況はSEO上かなりネガティブになり得ることですので、きちんと整備しておくことに越したことはありません。
さてようやく本題です。
まず最初に考えるべきは「重複させないための仕組み」
冒頭の例に戻りますが、ああいう形での重複データがあると、検索して最新状況確認する際に色んなとこに情報が散らばってたりしていて、「誰だよこっち書いた奴、こっちにまとめろよ」みたいなことになるわけですね。
この状態は間違いなく色々不便かつ正しくない状態なので、避けるべきことです。
1つ2つあるだけならまだしも、これが数百とかに渡って大量の重複データがシステム内に存在する、あちこちに情報が散乱してまとまってない、みたいな状態になっていたらもうカオスですよね。
で、この時にその部署の管理者が真っ先に考えるべきことって、「重複が原因で顧客データに不備があってで何かトラブルが発生したときの対応策」とか「重複データをどのデータにまとめるかのルール」ではなくて「重複データが発生しないための仕組み」ですよね。
予めシステム側で上手く照合されるように良い塩梅の条件決めておくとか、オペレーター側での指導や管理の徹底だったりとか、そういうことで問題が起こらないように仕組みを作っておくわけです。
最近LINEマンガでROOKIESを久々に読んだのですが、
「あらかじめ打球を予測していとも簡単に捕る。それが本当のファインプレーだ」
と池辺教頭もおっしゃっていまして、それと同じ理屈です。
コンテンツに対してURLが一意であることが理想
SEOに話を戻します。前の話をURL正規化の話に無理やり帰着させて、「URLがばらけるから正規化しよう」ではなくて「URLがばらけないように作ろう」が先にあるべきだ、という話ですね。
テクニカルに「こうすればいいんです!」みたいな応急処置を積み重ねていくと、後々どこでどんな処理をしていたかとか分からなくなったりリニューアルの際に抜け漏れが発生したり、あまり良いことはありません。
もちろん、www.とか拡張子とか「/」有無とかutm系のパラメータとかそういう当たり前に発生するものはいつも通りの転送やcanonicalなどで正規化処理をする必要がありますので(今回は解説割愛)、そういうもの以外での不要な正規化処理を避けようとすることが大事ということです。
分かりやすい例で言えばクロスカテゴリ(財布(アイテム)×シャネル(ブランド)みたいにあるカテゴリと別のカテゴリとの掛け合わせ)が発生するようなサイトでこういう形を稀に見ます。
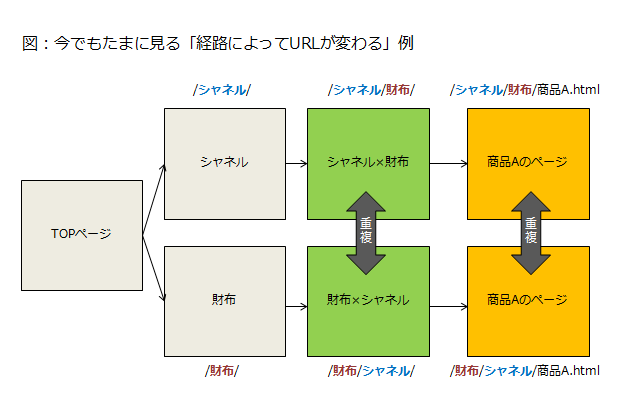
こういう仕様でガッチリとシステムを固めてしまうとあまり簡単にはいじれなくなりますので無理やりcanonicalで対応するような処理をする必要が出てきます。
この場合は、複数の可能性が考えられる経路やカテゴリに、クロスカテゴリのURLや商品ページのURLが依存してしまってるのが問題ですね。
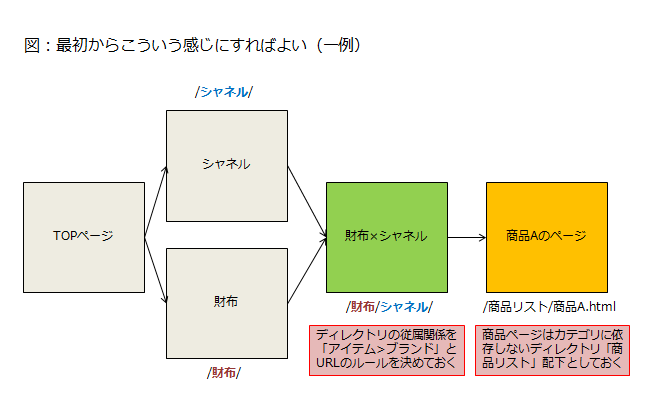
これは一例ですが、このように商品のURLはカテゴリや経路に依存しない仕様にしておかないと、というような配慮があれば正規化処理などここではもともと考える必要もなかったわけです。
よほど大規模だったり複雑なサイトでなければ、最初にURLについて考えておけば大抵の問題は回避できるんじゃないかなと思います。それなのに「URLもちゃんと考えておかないと」って考えて設計しようとしている方って意外に少ない気がします。
あるコンテンツに対してURLは一意、が基本
「ひとつのコンテンツに対してURLがひとつ」であるべきで、余計な正規化処理をしなくてよいURLの設計を心がけてみてください。
SEOってサイトとかページとかではなく本質的にはURL単位でクロールされ、URL単位でインデックスに格納され、URL単位で評価が付きます。そういう意味ではURL設計を考慮することは基本的なSEOのひとつです。
仕事柄、色んなエンジニアの方と話す機会ありますが、「URLをどう吐きだすかとか深く考えたことなかったッスねー」という感じの人は (受託開発してるとかメディア運営してるとか関わらず)多かったりします。
特に幅広いコンテンツを扱うとか大量のコンテンツを扱う、とかの場合、このあたりのURLの考慮の有無によって後々余分な処理をするための工期が削減できる、改修や拡張が入った時にも変更が少なくて済む、変更が少なくて済むということは実装ミスによる検索トラフィック損失などのリスクが減らせる、というわけです。
補足:検索エンジンが進化しても機械への配慮はしておく
「Googleも上手く対処できるようになってるから細かいことはあんまり気にしなくていいよ」とはGoogleがよく言っていることで、確かにそうなってきています。しかしここは受け手としては「検索エンジンの技術に合わせることに躍起になってコストかけなくていいよ(Googleが頑張るからさ)」と捉えたいところ。
サイトを作る方は、「それでもサイトを制作する時には(検索エンジンに限らず)機械への配慮を怠らない」と考えるべきと思います。SEOに限って言えば、そうすることで防げる損失がかなり大きい場合も珍しくありません。
ということで、この記事を読んで「へぇそういうこともあるのか」と感じた方は、是非参考にしてみてください。
SEO対策の基本のHTMLであるタイトルタグの付け方を知りたい方はこちら
ナイル株式会社 土居
SEO対策の悩みをプロに相談してみませんか? SEOやWebマーケティングの悩みがありましたら、お気軽にナイルの無料相談をご利用ください!資料では、ナイルのSEO支援実績(事例)、コンサルティングの方針や進め方、費用の目安といった情報をご紹介しています。あわせてご覧ください。
「ナイルのSEO相談室」は業界歴15年超のナイルが運営しているメディアです。SEOの最新情報を随時発信しているので、ぜひブックマークしてください!
またSEOにお悩みの方は無料相談やSEOコンサルティングサービスのご利用もぜひご検討ください!


著者

編集者
2007年に創業し、約15年間で累計2,000社以上の会社にマーケティング支援を行う。また、会社としても様々な本を出版しており、業界へのノウハウ浸透に貢献している。(実績・事例はこちら)



PIVOTにもスポンサード出演しました!

動画内では、マーケティング組織立ち上げのための新しい手段についてお話しています。
マーケティング組織に課題がある方はぜひご覧下さい。
動画を見る