構造化データとは、Webページの内容を検索エンジンに正確に伝えるためのデータ形式のこと。
適切に実装することで、検索結果でのリッチリザルト表示や音声検索への対応など、さまざまなメリットが期待できるでしょう。
この記事では、構造化データの基本的な仕組みや具体的な設定・検証方法、注意点について詳しく解説します。
SEOの基礎知識 TOPページへSEO対策の悩みをプロに相談してみませんか?

SEOやWebマーケティングの悩みがありましたら、お気軽にナイルの無料相談をご利用ください!資料では、ナイルのSEO支援実績(事例)、コンサルティングの方針や進め方、費用の目安といった情報をご紹介しています。あわせてご覧ください。
目次
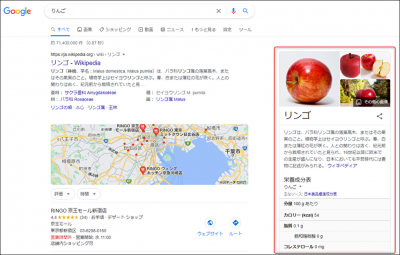
構造化データとはどういうもの?
構造化データとは、検索エンジンにページの内容を正確に伝えるためのデータ形式のことです。
例えば、人間が見れば「これは商品情報だ」「これはイベント情報だ」と理解できるページ内容も、検索エンジンからすると“ただの文字列”であって、(ある程度はわかるものの)完全に内容を理解できるわけではありません。
そこで、ページ内の情報を「これは商品名」「これは価格」「これは開催日」といった形でわかりやすくマークを付けてあげる――それが構造化データの役割です。
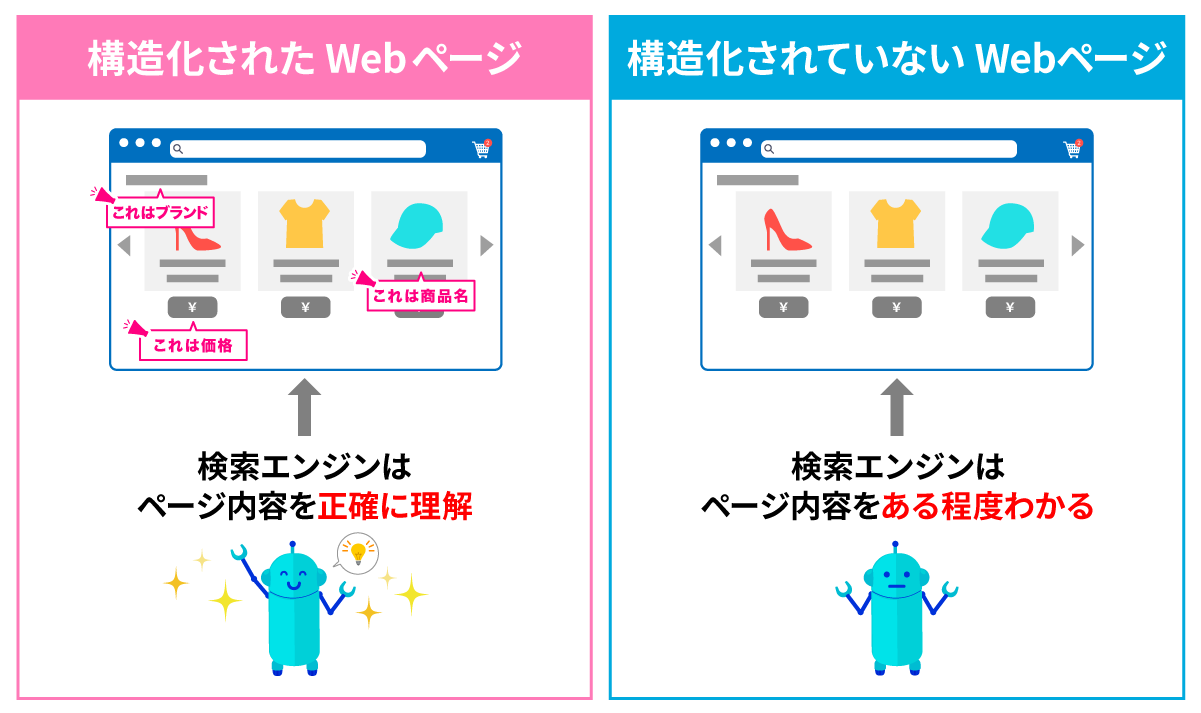
なお、構造化データはGoogleも実装を推奨している施策(※)。
正しく設定することで、検索結果で「星評価」や「パンくずリスト」などの「リッチリザルト」が表示されることもあり、クリック率の向上につながると考えられます。
※参考:Google 検索における構造化データのマークアップの概要 - Google Search Centralブログ
「構造化データ」と「構造化マークアップ」の違い
「構造化データ」と「構造化マークアップ」は混同されがちな言葉ですが、厳密には意味が異なります。
- 構造化データ…検索エンジンに伝えるための、決まった形式で記述されたデータそのもの
- 構造化マークアップ…そのデータをWebページに実装する作業や方法
つまり、構造化データという「情報」を、構造化マークアップという「手段」を使ってページに組み込む、という関係です。
実際の会話では、どちらの言葉も同じような意味合いで使われることが多いため、あまり神経質になる必要はありませんが、「構造化データのマークアップ」が正確な表現になります。
構造化データの記述形式「Schema.org」
構造化データを記述する際に使われる共通仕様が、「Schema.org(スキーマ・ドット・オルグ)」です。
これは、GoogleやMicrosoft、Yahoo!などの主要な検索エンジンが共同で策定した“共通言語”のようなもの。
この仕様に従って記述することで、どの検索エンジンでも同じように情報を理解できます。
Schema.orgでは、記事ページで使う「Article」、商品ページの「Product」、イベントページの「Event」などのタイプごとに、「どんな情報を、どんな形で構造化するか」があらかじめ定義されています。
<「Event」の構造化データのプロパティ(タグ)の一部>
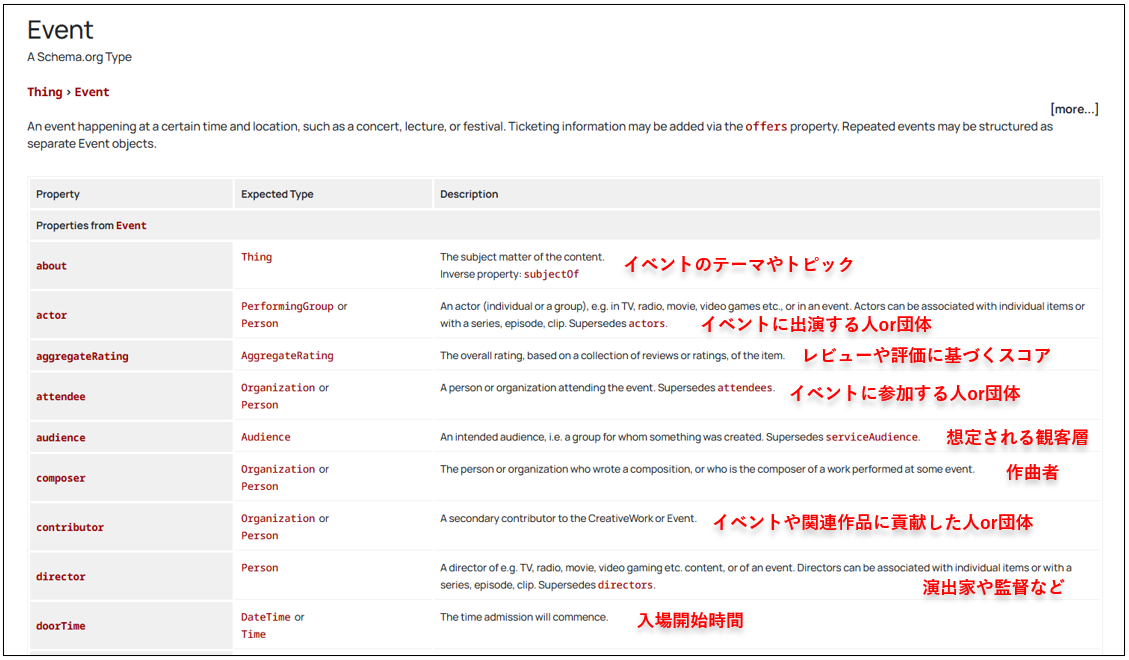
これに従ってマークアップすることで、検索エンジンがページ内容をより深く理解できるようになるのです。
構造化データの主なタイプと活用例
前項でふれたとおり、構造化データはSchema.orgで定義された「Article(記事)」「Product(商品)」「Event(イベント)」などのタイプがあり、タイプごとに「どんな情報をどう整理して伝えるか」が決められています。
こうして構造化データを設定することで、検索エンジンがページ内容をより正確に理解できるようになり、一部のタイプではリッチリザルト(検索結果での強調表示)が適用されることもあります。
<リッチリザルトの表示例>
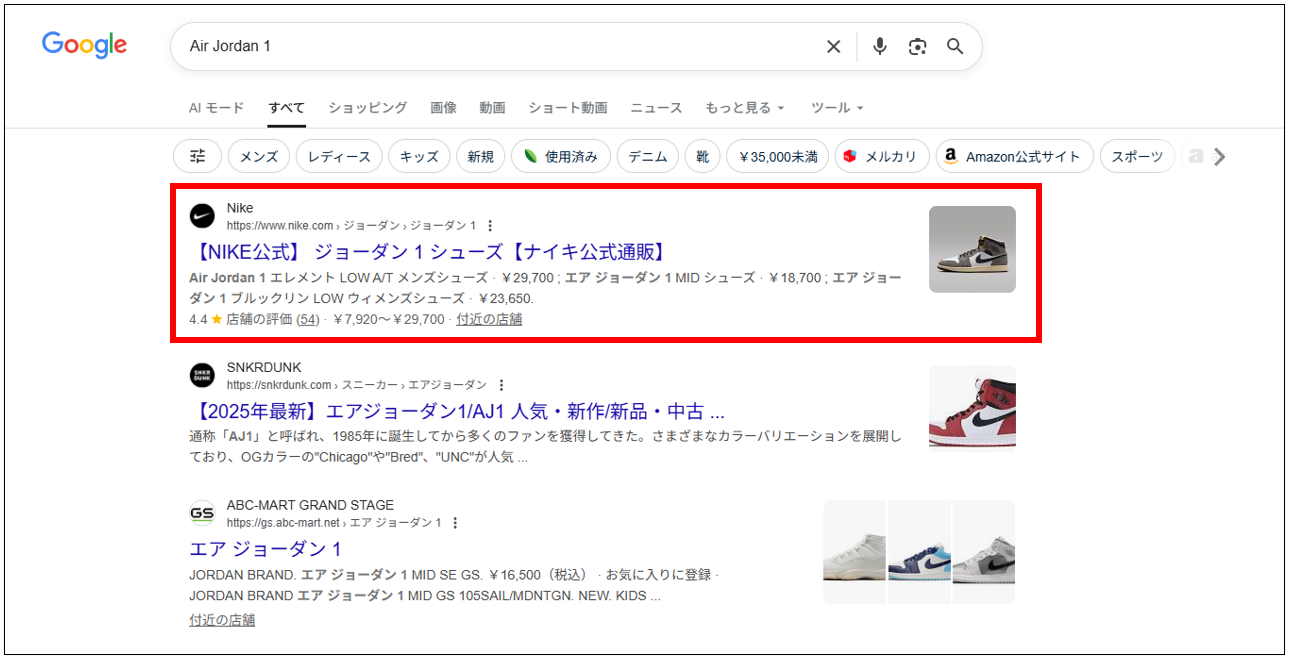
Productの表示例
ただし、構造化データを実装することで必ずリッチリザルトが表示されるわけではなく、サイト運営者側も表示の有無をコントロールできません。
では、構造化データの主なタイプと活用シーン、リッチリザルト表示の可能性の有無を下表で紹介しましょう。
<構造化データの主なタイプと活用シーン>
| タイプ | 活用シーン | リッチリザルト対応 |
|---|---|---|
| FAQ | よくある質問をまとめたページ 製品の使い方やサービスに関する疑問など |
× |
| Article | ニュース記事やブログ記事 記事のタイトル、公開日、著者名などを設定 |
○ |
| Breadcrumb | パンくずリスト ページの階層構造を検索結果に表示 |
○ |
| Product | 商品情報 商品名、価格、在庫状況、レビューの星評価などを表示 |
○ |
| Event | イベント情報 セミナーやコンサート、展示会の開催日時や場所などを表示 |
○ |
| LocalBusiness | 店舗や施設の情報 店舗名、住所、営業時間、電話番号などを設定 |
○ |
| How-to | 手順を説明するコンテンツ 料理のレシピやDIY、製品の組み立て方など |
○ |
| Organization | 企業や組織の情報 企業名、ロゴ、所在地、SNSアカウントなどを設定 |
△(※) |
| WebSite | Webサイト全体の情報 サイト名や検索ボックスの設定。サイト内検索機能の提供 |
× |
| Person | 人物情報 著者プロフィールや専門家の経歴などを設定 |
× |
※Organizationは、ナレッジパネルへの情報提供には役立つが、通常の検索結果でのリッチリザルトとしては表示されない。
ここで紹介したタイプは、ごく一部のよく使われているものです。
Googleがサポートしている構造化データのタイプはほかにも多数あり、下記の公式ドキュメントで詳しく確認できます。
Google 検索がサポートする構造化データ マークアップ - Google Search Centralブログ
詳しくはこの記事もチェック!

構造化データを実装するメリット
構造化データを設定することで得られるメリットを紹介します。
<構造化データを実装するメリット>
間接的に検索順位の向上に貢献する可能性がある
構造化データを設定しても、それ自体が直接的なランキング要因として検索順位を上げるわけではありません。
しかし、検索エンジンがページ内容をより正確に理解できるようになることで、その情報が適切な検索意図(クエリ)と結びつきやすくなる効果があります。
結果として、ユーザーの検索意図に合致する機会が増え、関連キーワードでの評価やクリック率の改善につながる可能性があるでしょう。
また、構造化データを通じて検索エンジンに「このページは専門的で、体系的に整理されている」というシグナルを送ることは、中長期的にサイト全体の信頼性や評価の底上げにもつながります。
直接的なSEO施策というよりも、検索エンジンにページ内容を正しく理解してもらう土台を整えることで、評価の機会を広げる施策と捉えるのが適切です。
リッチリザルトが表示された場合、クリック率の向上が期待できる
リッチリザルトは、通常のタイトルとディスクリプションだけの表示に比べて、画像や星評価、価格、FAQなどの追加情報が表示されるため、検索結果上で目立ちやすくなります。
ユーザーは検索結果を上から順に眺めていく際、視覚的に目を引くリッチリザルトに注目しやすく、「このページには自分が求めている情報がありそうだ」と判断しやすくなるでしょう。
そのため、リッチリザルトが表示されることでクリック率(CTR)が向上したケースは少なくありません。
もちろん、構造化データを設定したからといって必ずリッチリザルトが表示されるわけではありませんが、表示されることを前提に設定しておくことが大切です。
AIの理解を助け、音声検索やLLMOに貢献する
構造化データは、検索エンジンだけでなく、AIがページ内容を正確に理解するための重要な手がかりにもなります。
例えば、音声検索ではユーザーの質問に対して「どのページが最も的確な答えか」をAIが判断しますが、構造化データで「これはFAQの質問」「これは回答」と明示しておくことで、AIがより適切な回答を導きやすくなります。
また、LLMOにおいても、構造化データによって整理された情報は活用されやすいと考えられています。
例えば、FAQやProduct、Organizationなどの構造化データを明示しておくと、AIが回答を生成する際にその情報をより正確に引用・要約できるようになるでしょう。
構造化データの設定方法
構造化データの実装と聞くと、「コーディングの知識が必要で難しそう」と感じるかもしれません。
しかし実際には、ツールを使えば比較的簡単に設定できますし、手動で書く場合もそれほど複雑ではありません。
ここでは、構造化データの記述方法や具体的な設定の仕方を解説していきます。
記述方法は「JSON-LD形式」を推奨
構造化データの書き方には、主に次の3種類がありますが、現在はJSON-LD(ジェイソン・エルディー)形式が推奨されています。
<構造化データの記述方法>
| 形式 | 特徴 | 難易度 |
|---|---|---|
| JSON-LD | JavaScript形式でページ内に独立して記述できる HTMLを直接編集する必要がない |
最も保守しやすく、CMSやGoogleタグマネージャーでも対応可能 |
| Microdata | HTMLタグ内に属性として直接記述する形式 | HTML構造が複雑になりやすく、編集・修正が難しい |
| RDFa | Microdataに似ているが、より柔軟なメタデータ表現が可能 | 専門的な用途が多く、一般的なWebページではあまり使われない |
コードの生成・記述方法
構造化データのコードを用意する方法は、「ツールを使って自動生成する」方法と、「手動でコードを書く方法」の2つあります。
それぞれの特徴を理解して、自分に合った方法を選びましょう。
<コードの生成・記述方法>
ツールを使って自動生成する方法
コーディング知識がなくても、ツールを使えばフォーム入力やクリック操作だけでJSON-LDを生成できます。
ここでは、Googleが提供している「構造化データ マークアップ支援ツール」を用いて、「ナイルのSEO相談室」のページの構造化データを生成してみましょう。
<Google「構造化データ マークアップ支援ツール」でコードを生成する方法>
- 構造化データのタイプを選択する
トップページから、構造化データのタイプを選んで該当のURLを入力するか、まだ公開されていない場合はHTMLを貼り付けて、「タグ付けを開始」をクリック。
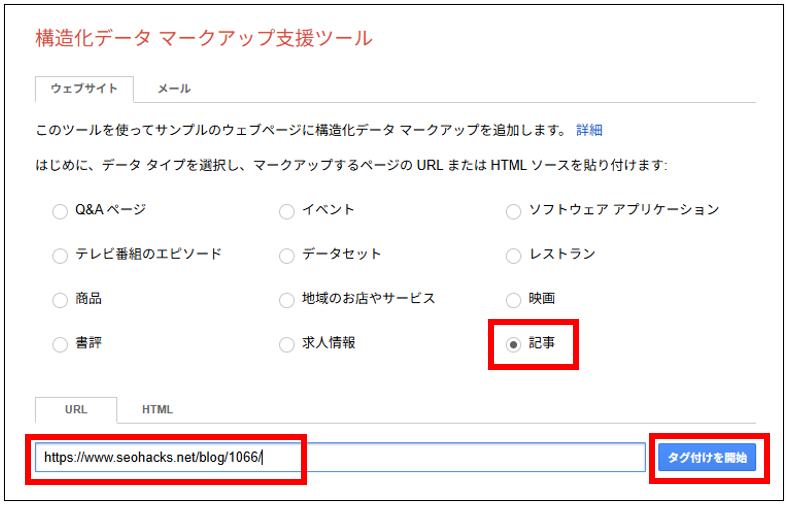
- ページ上の要素をタグ付けする
ページが読み込まれたら、画面左側に表示されたページプレビューから「タイトル」「著者名」「公開日」など(右側の「レコード」欄に記載されている項目)、推奨されるタグ(プロパティ)をマウスで選択していきます。
なお、必須となっているタグ(記事タイプなら「タイトル」)以外は空欄でも問題ありませんが、検索エンジンが記事を正確に理解するためには、可能な限り多く設定しましょう。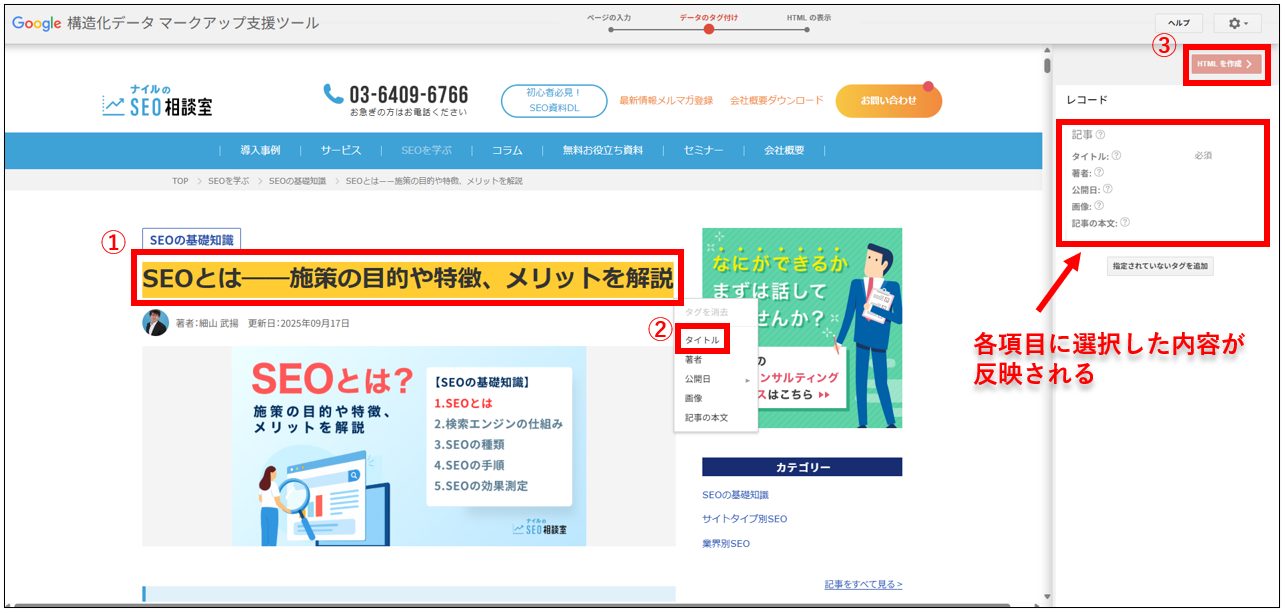
- コードを取得する
設定したタグをもとに、JSON-LD形式のコードが生成されます。それをコピー、もしくはダウンロードしましょう。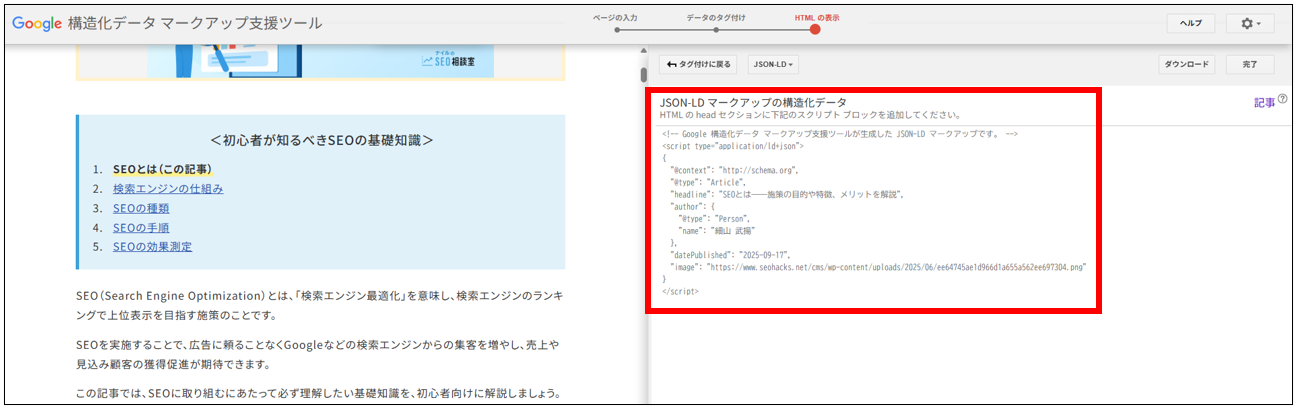
なお、「構造化データ マークアップ支援ツール」以外にも、下記のような無料で使える構造化データ生成ツールがあります(すべて英語対応、入力は日本語でOK)。
<無料で使える構造化データ生成ツール>
いずれも構造化データのタイプを選択し、タグを直接入力していくスタイル。フォームに従って入力すれば、JSON-LD形式のコードを生成できます。
手動でコードを書く場合
構造化データのコードを手動で書くメリットは、細かいカスタマイズが可能なことと、自分のペースで学びながら実装できることです。
ここでは、よく使われるタイプの書き方の例を紹介します。
各コード例では、運営者が自サイトに合わせて入力・変更する部分にコメント(// ← ~)を付けています。
<Article(記事)の例>
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "SEOとは――施策の目的や特徴、メリットを解説", // ← 記事タイトルを入力
"image": " https://www.seohacks.net/cms/wp-content/uploads/2025/06/ee64745ae1d966d1a655a562ee697304.png", // ← アイキャッチの画像アドレスを入力
"author": {
"@type": "Person",
"name": "細山武揚" // ← 著者名を入力
},
"publisher": {
"@type": "Organization",
"name": "ナイル株式会社" // ← 運営組織名を入力
},
"datePublished": "2025-07-09", // ← 公開日を入力(YYYY-MM-DD形式)
"dateModified": "2025-09-17" // ← 更新日を入力(YYYY-MM-DD形式)
}
</script>
<Breadcrumb(パンくずリスト)の例>
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "BreadcrumbList",
"itemListElement": [
{
"@type": "ListItem",
"position": 1, // ← 階層の順番(1から始まる連番)
"name": "ホーム", // ← 階層の名前を入力
"item": "https://example.com/" // ← 階層のURLを入力
},
{
"@type": "ListItem", //
"position": 2, // ← 階層の順番
"name": "SEOブログ", // ← 階層の名前を入力
"item": "https://example.com/blog/" // ← 階層のURLを入力
},
{
"@type": "ListItem",
"position": 3, // ← 階層の順番
"name": "構造化データとは", // ← 階層の名前を入力
"item": "https://example.com/blog/structured-data/" // ← 階層のURLを入力
}
// ← 階層を追加する場合は、同じ形式で繰り返す
]
}
</script>
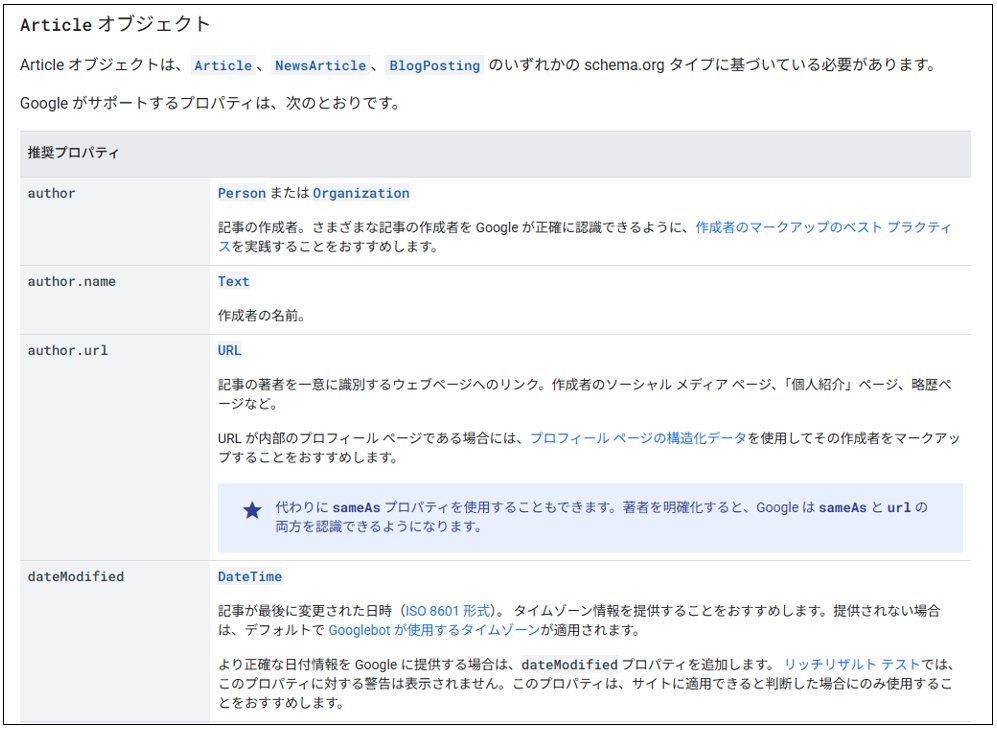
なお、各構造化データのタイプで推奨されるタグ(プロパティ)、コードのテンプレートは、Googleの公式ドキュメントやSchema.orgの公式サイトで確認できます。
各々の確認方法は次のとおりです。
<Googleの公式ドキュメント>
Google検索がサポートする構造化データの種類一覧のページから、目的のタイプの「スタートガイド」を確認してください。
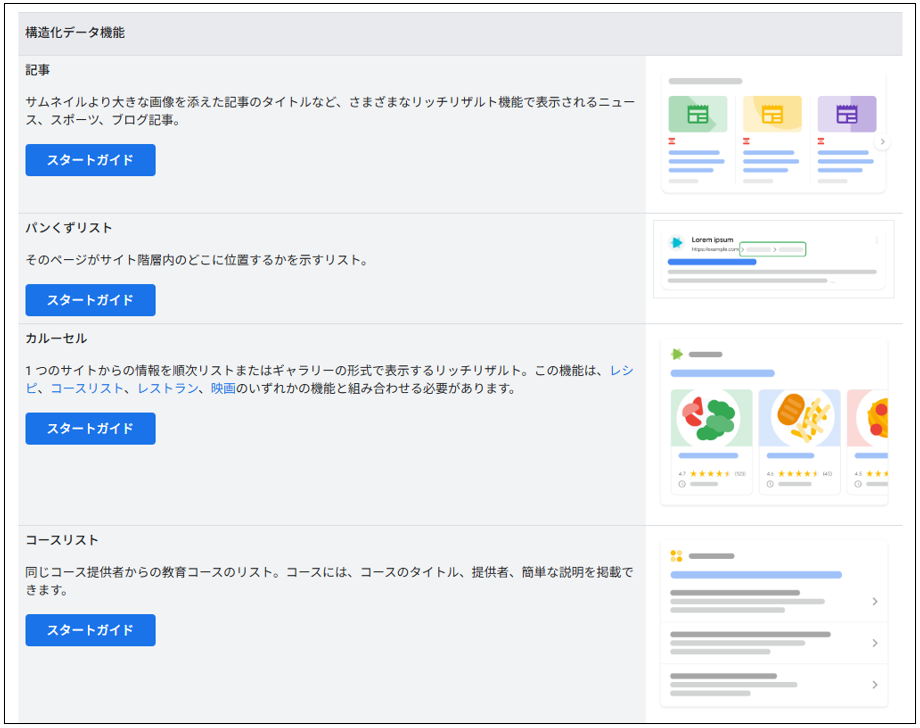
参考:Google検索がサポートする構造化データのマークアップ - Google Search Centralブログ
各タイプのスタートガイドには、JSON-LDのサンプルコードと、推奨されるタグ(プロパティ)が記載されています。
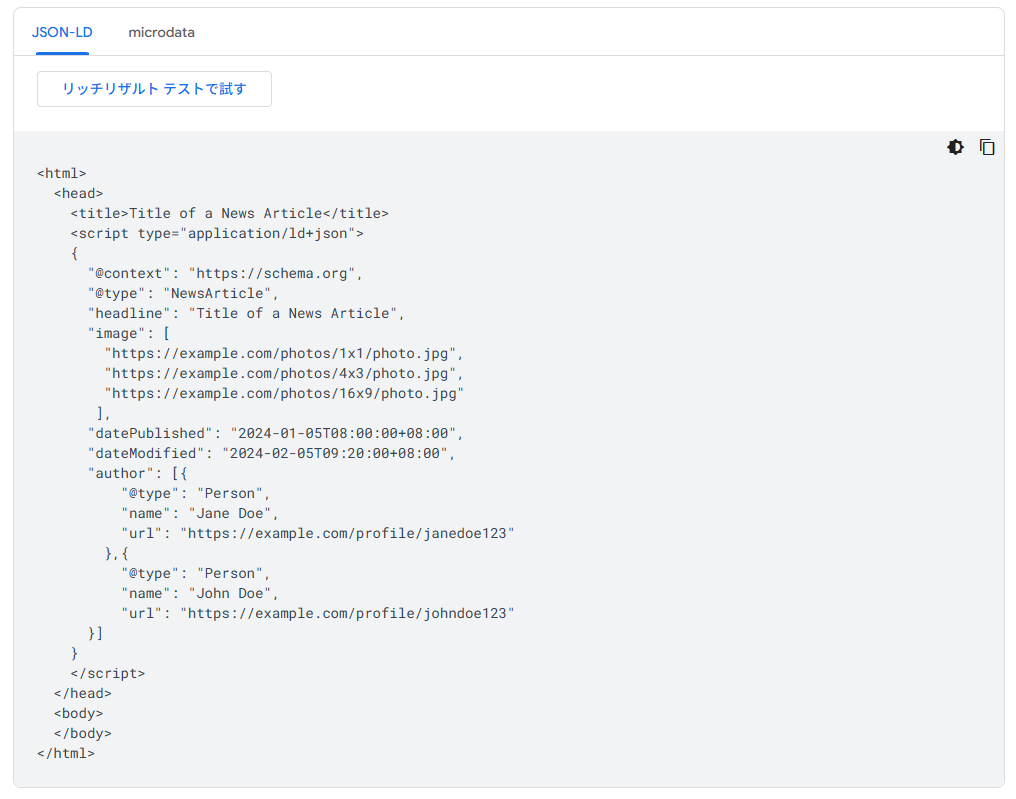
参考:記事(Article)の構造化データ - Google Search Centralブログ
<Schema.orgの公式サイト>
Schema.orgの公式サイトにある「Schemas」カテゴリのトップページから、各タイプのページへ飛ぶことができます(すべて英語)。
しかし、リストから探すのは大変なので、確認したいタイプを右上の検索窓に入力するほうがいいでしょう。
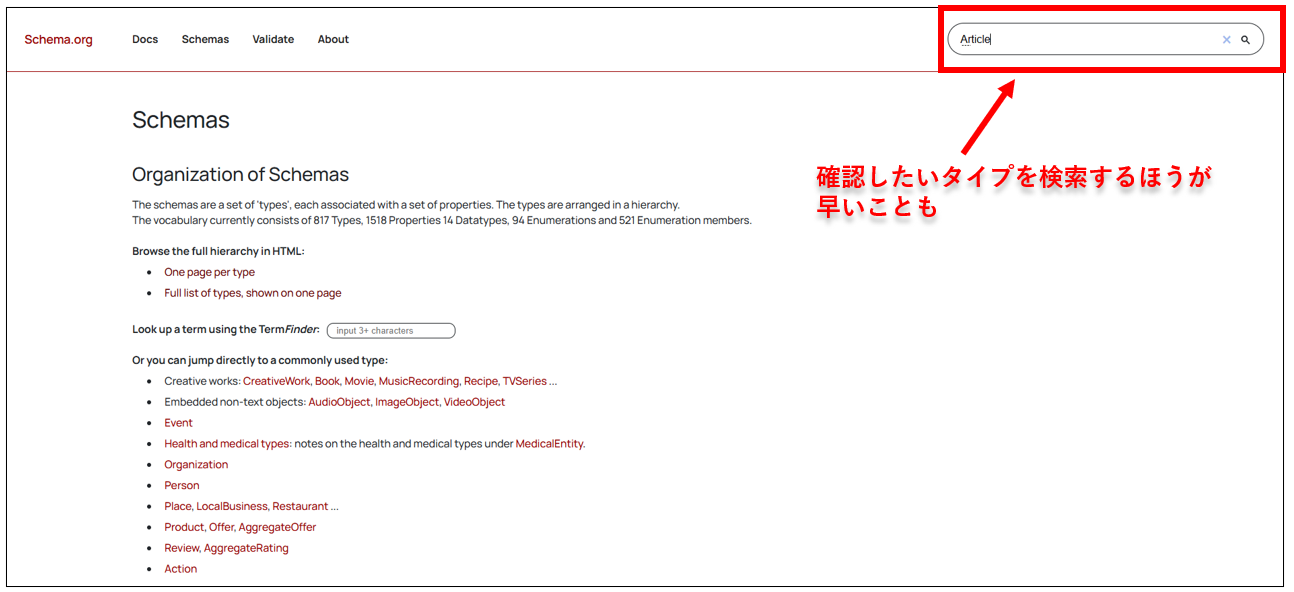
各タイプのページでは、タグ(Property)の紹介とサンプルコード(Examples)が記載されています。
なお、この場合もすべてのタグを記載する必要はありませんが、できる限り設定するといいでしょう。
CMSでの設定方法
構造化データが生成されたら、CMSに実装していきましょう。
ここでは、WordPressでの実装方法を紹介します。初心者は主に次の2つの方法がおすすめです。
プラグインを使う
最も手軽な方法は、構造化データに対応したプラグインを使うことです。
代表的なプラグインには次のようなものがあります。
<構造化データのプラグイン>
- Yoast SEO
SEOプラグインとして有名で、構造化データも自動で出力してくれる - All in One SEO
こちらもSEO総合プラグインで、構造化データ機能を搭載 - Schema & Structured Data for WP & AMP
構造化データ専門のプラグイン。細かい設定が可能
利用しているテーマの機能を使う
最近のWordPressテーマには、構造化データ出力機能が標準搭載されているものもあるため、プラグインをインストールする必要がないケースも。
例えば、SWELLやJIN、AFFINGER、Cocoonといったテーマでは、記事ページやパンくずリストなどの基本的な構造化データを自動生成してくれるため、手動でコードを追加する必要はありません。
どのタイプの構造化データが出力されるかはテーマによって異なるため、各テーマの公式サイトやマニュアルで概要を確認しましょう。
構造化データのテスト・検証方法
構造化データをマークアップする際は、必ず動作確認を行いましょう。
必須プロパティの欠落や形式の不備、値の型の誤りなどが起こりやすいため、実装前後の確認は必須です。
特に手動でコードを記述した場合、カンマやカッコの抜け、プロパティ名のスペルミスなど、些細なミスでエラーになることがあります。
ここでは、3つの検証ツールを使った確認方法を見ていきましょう。
<構造化データの検証ツール>
スキーマ マークアップ検証ツール
スキーマ マークアップ検証ツールは、構造化データの内容が正しく記述されているかをチェックできるツールです。
このツールの特徴は、Schema.orgの規格に準拠しているかどうかを確認できる点。
構造化データの「文法」が正しいかをチェックするツールといえます。
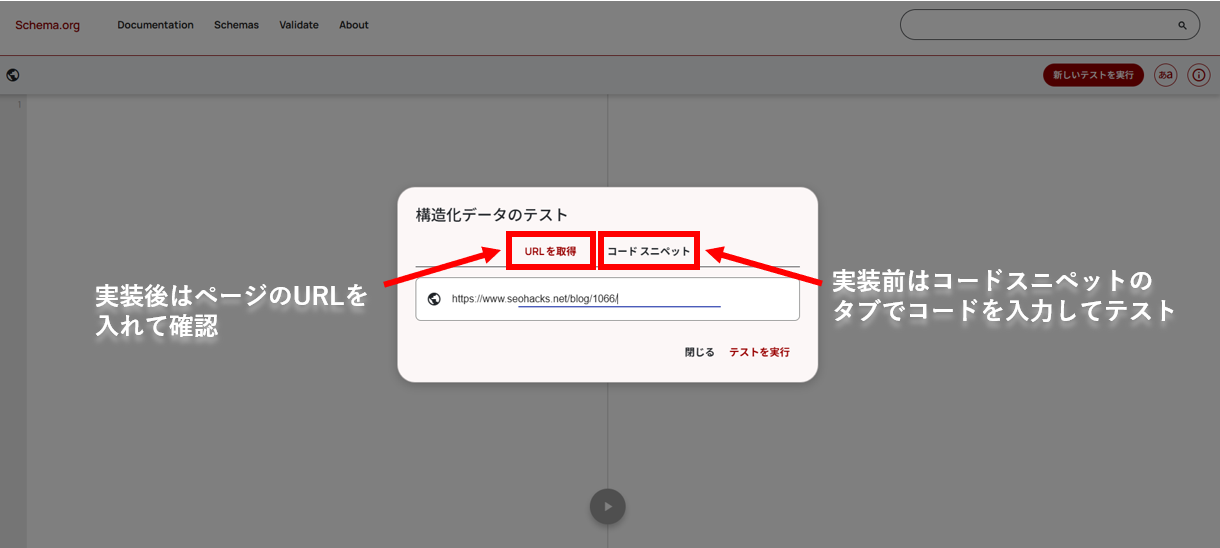
<確認手順>
- 実装したページのURL、もしくはコードを入力して「テストを実行」をクリック
実装前は「コードスニペット」タブに生成した構造化データのコードでテストし、実装後は「URLを取得」タブでページのURLを入力してテストをするのがいいでしょう。
- テストの結果が表示される
問題ない場合は「エラーなし」と表示。コードに誤りがある場合は、「アイテムが検出されませんでした」と表示され、エラーの内容も確認可能です。
コードを修正し、改めてテストを行いましょう。
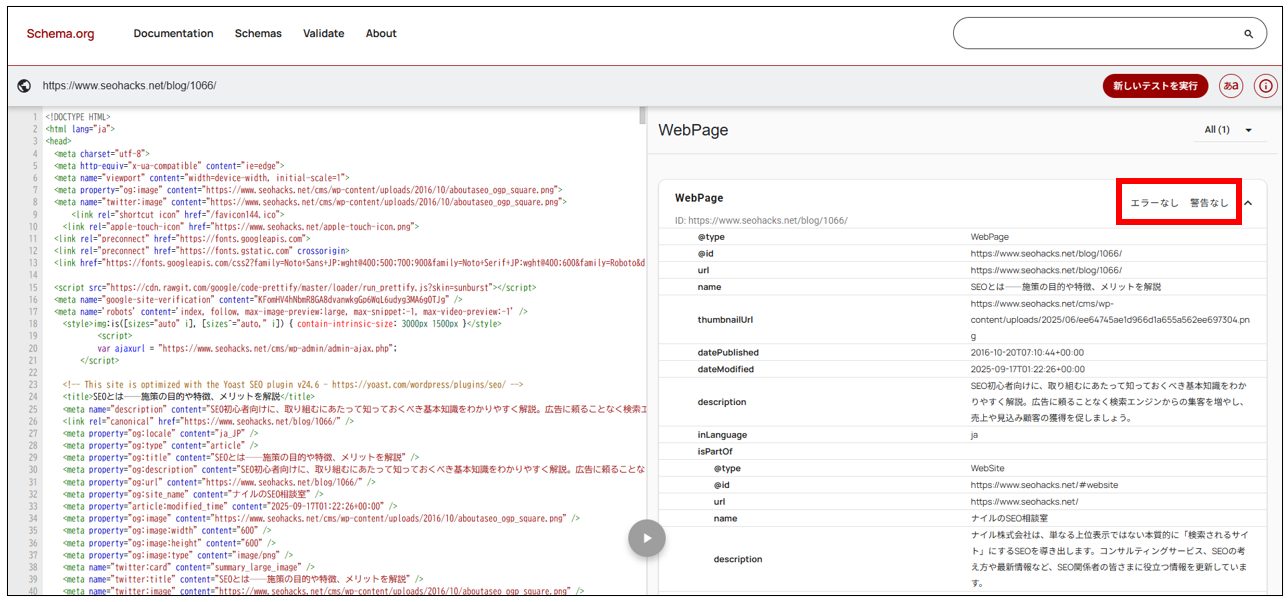
エラーがない場合の表示

エラーがある場合の表示
リッチリザルトテスト
リッチリザルトテストは、設定した構造化データがGoogleのリッチリザルトとして有効かどうかをチェックできるツールです。
このツールの特徴は、「Googleの検索結果でリッチリザルトとして表示される可能性があるか」を確認できる点です。
構造化データが正しく記述されていても、Googleの要件を満たしていなければリッチリザルトとして表示されません。
<確認手順>
- 実装したページのURL、もしくはコードを入力して「テスト」をクリック
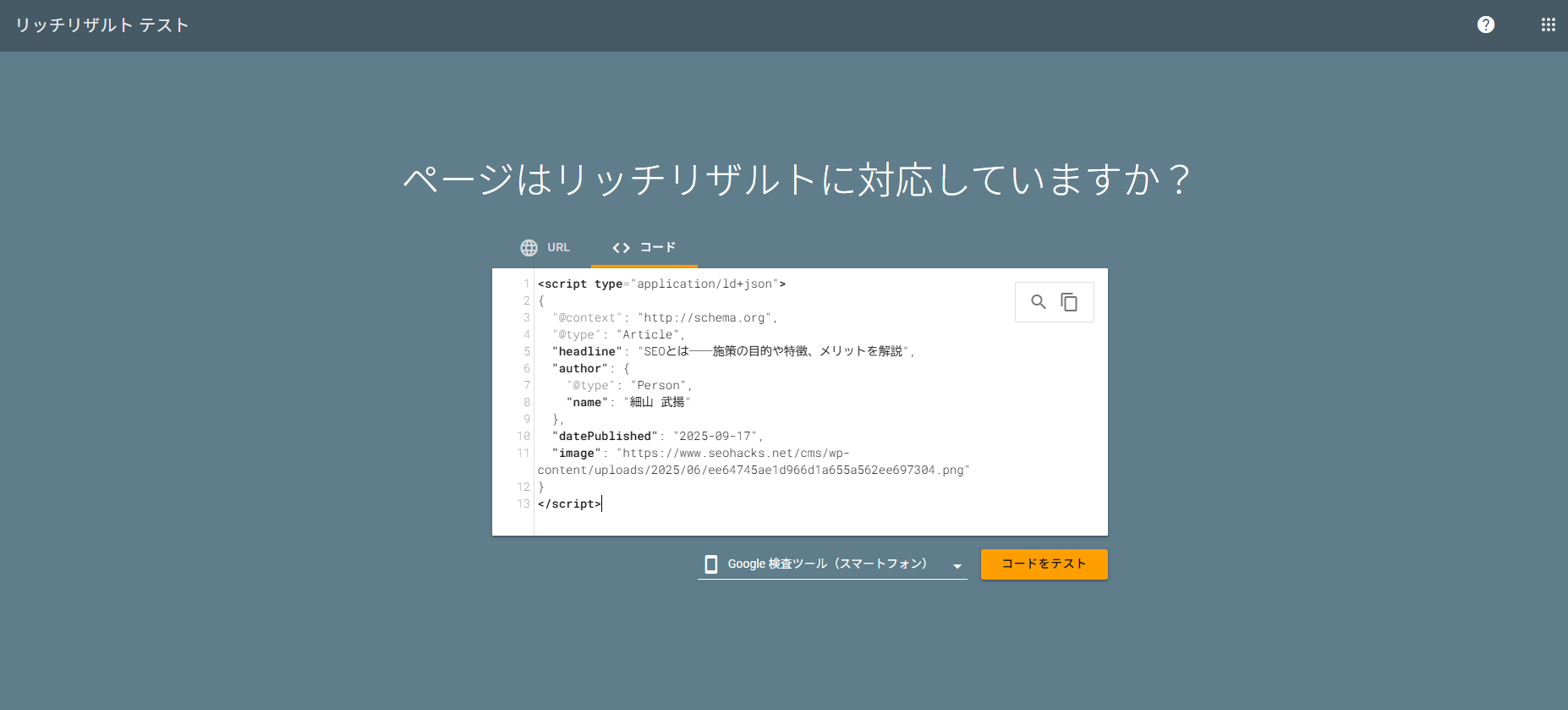
- テスト結果を確認
こちらもエラーがある場合は、エラーの内容を確認することができます。
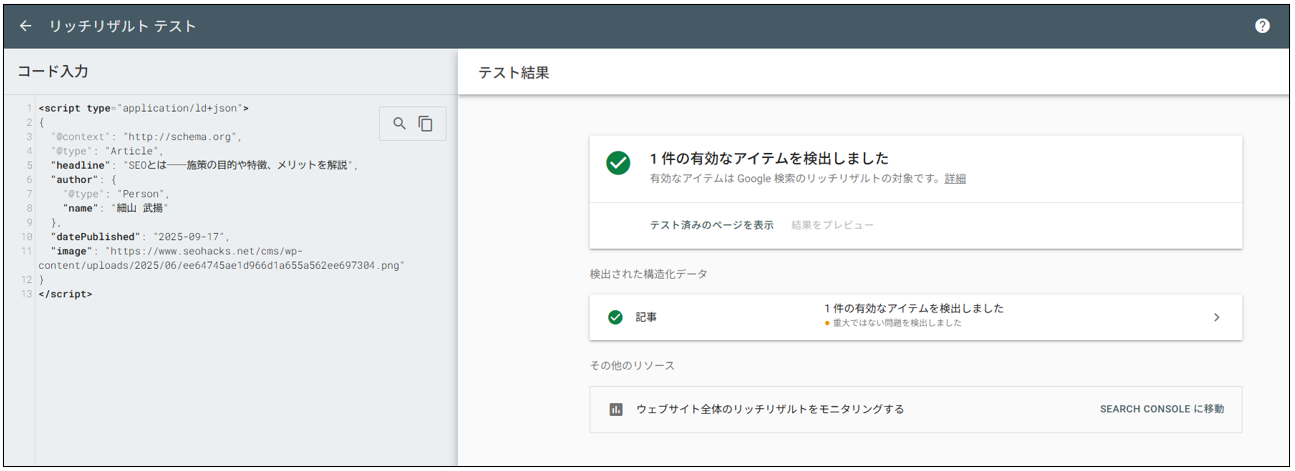
エラーがない場合の表示
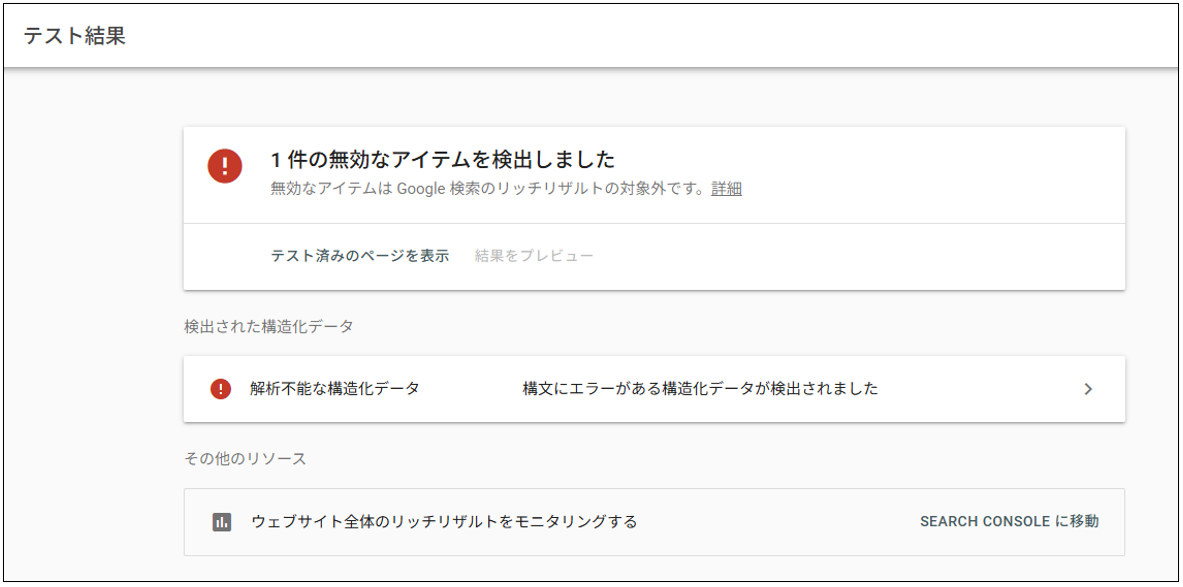
エラーがある場合の表示
Google Search Console
Google Search Consoleでは、構造化データのタイプ別に設定エラーがないかを確認できます。
<確認方法>
- 構造化データのタイプ別に確認
左メニュー「拡張」内に、Webサイトに実装された構造化データのタイプが表示されます。
そのうち、確認したいタイプをクリックしましょう。
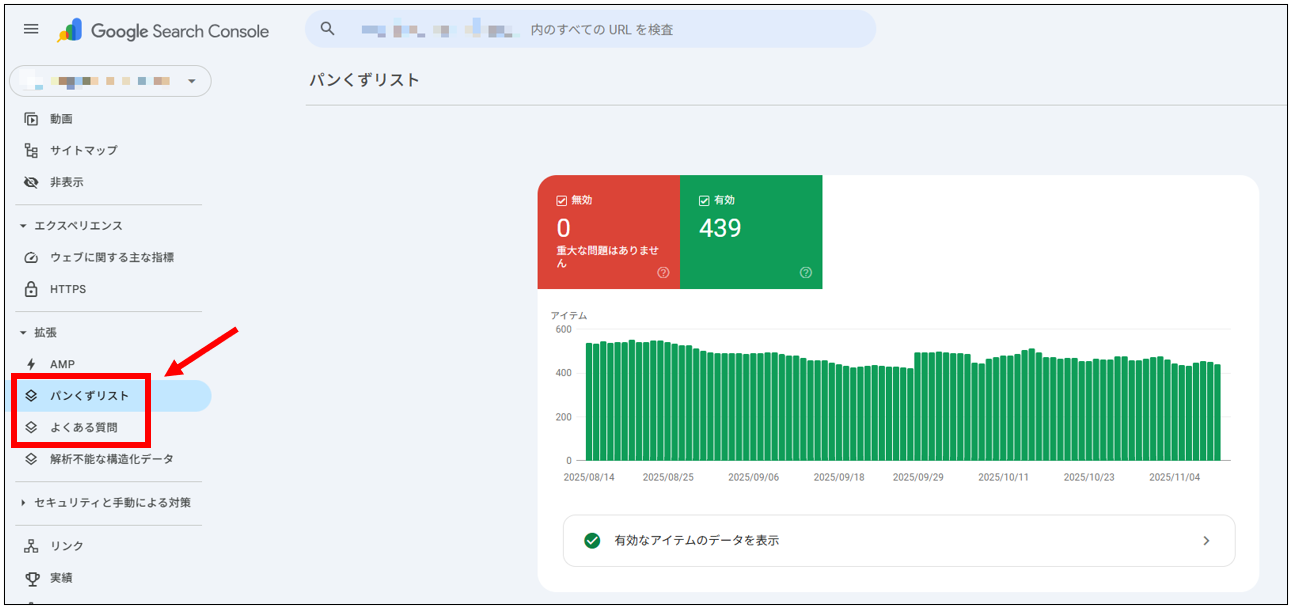
- エラーがある場合は修正
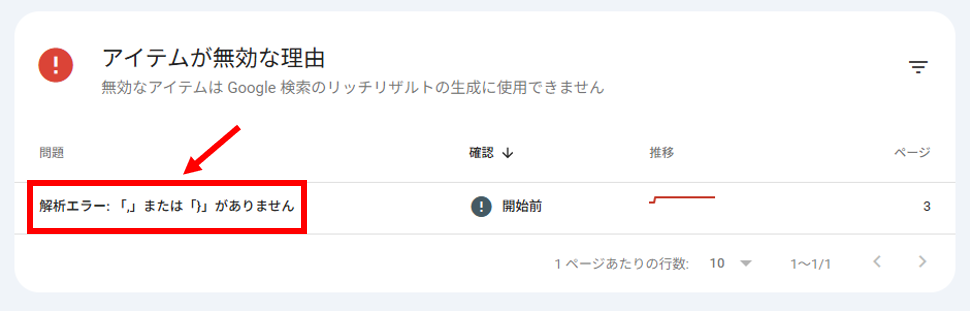
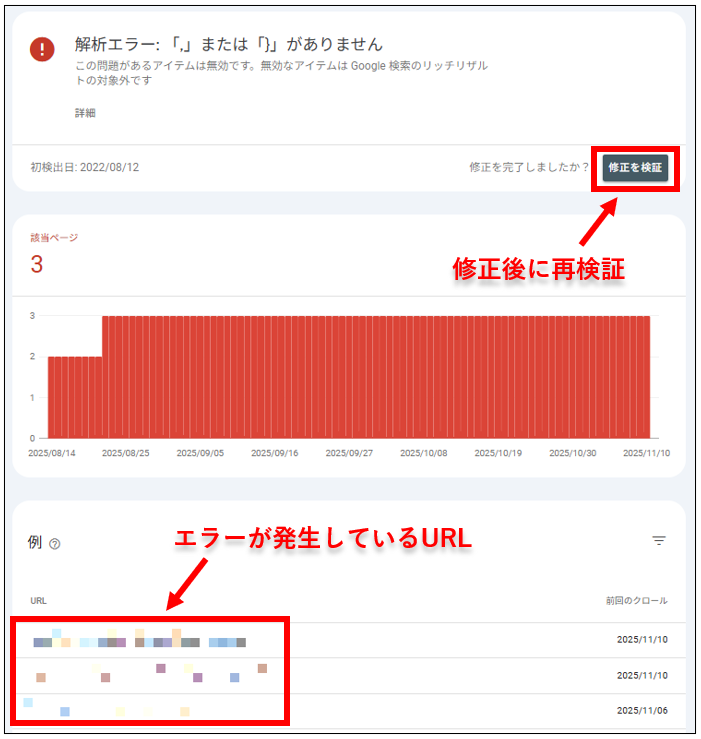
エラーがある場合は、「アイテムが無効な理由」欄に問題の詳細が表示されます。
問題をクリックして該当ページを確認し、修正しましょう。
その後、「修正を検証」をクリックして再チェックしてください。
構造化データの注意点
構造化データは正しく実装すれば大きなメリットが得られますが、誤った使い方をするとペナルティを受けるリスクがあります。
構造化データを実装する際に注意したいポイントを紹介しましょう。
<構造化データの注意点>
実際のページ内容と一致していない
構造化データで最も重要なのは、マークアップする内容が実際のページに表示されている情報と一致していることです。
Googleのガイドラインでは、ユーザーに見えていない情報を構造化データでマークアップすることを明確に禁止しています。
参考:Google 検索上の構造化データ ガイドライン - Google Search Centralブログ
例えば、次のようなことは絶対に避けましょう。
<マークアップのNG例>
- ページ内に存在しない情報:ページに実際には掲載されていない質問と回答を構造化データに含める
- 虚偽の評価をマークアップする:実際には存在しないレビューや星評価を設定する
- 誇張した情報:価格や在庫状況など、実際とは異なる情報を記載する
過剰なマークアップをしている
構造化データは有用ですが、多ければ多いほど良いものではありません。
SEO目的で不要な項目まで無理に設定すると、かえって逆効果になることがあります。
<過剰なマークアップの例>
- 関係のないタイプを複数設定する
ひとつのページに無関係な複数の構造化データタイプを詰め込む - すべてのプロパティ(タグ)を埋めようとする
必須でも推奨でもない項目まで無理に設定する - キーワードを詰め込む
descriptionやheadlineに不自然にキーワードを詰め込む
構造化データの目的は「検索エンジンにページの内容を正確に伝えること」なので、ページの内容と直接関係のある、本当に必要な情報だけをマークアップすることが大切です。
シンプルで正確なマークアップを心がけることで、検索エンジンからの信頼を得やすくなるでしょう。
定期的にメンテナンスする必要がある
構造化データの仕様はSchema.orgやGoogleの更新に合わせて変化します。
過去に有効だったプロパティ(タグ)が廃止されたり、新しい型が追加されたりすることもあるため、必要に応じて構造化データを更新することが大切です。
また、Google Search Consoleでは、構造化データに関するエラーや警告が自動的に検出されます。
特に次のようなときは、定期的にGoogle Search Consoleをチェックしましょう。
- テーマやプラグインを更新したとき
- 新しい記事テンプレートを導入したとき
- Google Search Consoleで「警告」「エラー」が通知されたとき
構造化データは「一度設定して終わり」ではなく、検索仕様の変化に合わせてアップデートしていくメンテナンス項目と考えてください。
構造化データはすべてのページに実装すべき?
構造化データは、すべてのページに実装する必要はありません。
ポイントは、構造化データのタイプ単位で優先順位を決めること。
例えば、次のようにページの目的や構造、実装する際の難易度に合わせて、優先順位を決めると効率的です。
<構造化データのタイプ別:実装優先度>
| タイプ | 実装優先度 | 実装難易度 | 理由 |
|---|---|---|---|
| BreadcrumbList
(パンくず) |
高 | 低
(システム化可能) |
Webサイト全体で共通化できる
テーマ設定で自動出力される場合も多い |
| Article
BlogPosting |
高 | 低
(CMS連携可能) |
ブログ記事・コラム・ニュース記事などには、基本的に設定したい |
| Product
LocalBusiness |
中~高 | 低
(システム化可能) |
ECサイトやサービスページ、店舗ページなどは優先的に実装 |
| Organization
WebSite |
中 | 低
(1ページのみ) |
Webサイト全体を通して一度設定すればOK
トップページや会社概要ページなどに実装 |
| FAQ
HowTo Event |
状況による | 中 | 対応ページのみに設定すればOK |
このように、優先度が高いもので、実装難易度が低いものから着手することで、無理なく効果的な運用ができるでしょう。
構造化データは検索エンジンとの「共通言語」
構造化データは、検索エンジンに「このページには何が書かれているのか」を正確に伝えるための共通言語。
人間にとっては当たり前に理解できるページ内の情報も、検索エンジンにとってはただの文字列であり、曖昧な理解にとどまってしまいます。
そのため、構造化データを実装することで検索エンジンがページ内容を正しく把握し、リッチリザルトの表示やAIの理解を促進することにつなげましょう。
初心者でも簡単に構造化データの生成・実装は可能です。本記事で紹介した方法を参考に、ぜひ取り組んでみてください。
SEOの基礎知識 TOPページへ「さらにSEOを学びたい!」という方へ




編集者
一般情報誌や音楽情報メディアの編集部を経て、2017年にナイルへ入社。コンテンツディレクターとして主に医療系、ライフスタイル系などさまざまなメディアで顧客支援を行う。現在は主に「ナイルのSEO相談室」の制作を担当。
SEO基礎知識 記事一覧
-
- LLMOの効果測定
- LLMO
- AI Overviews
- LLMマーケティング
- ローカルSEO
- Googleコアアップデート
- 構造化データ
- YMYL
- 強調スニペット
- ナレッジパネル
- リッチスニペット
- 内部リンク
全部みる 閉じる

-
全部みる 閉じる
-
- サブドメインとサブディレクトリ
- エンティティ
- コアウェブバイタル
- サイテーション
- SEO記事の作り方
- 検索ボリューム
- ディレクトリ
- リダイレクト
- ペルソナ
- 指名検索
- noindex
- nofollow
- HTTPS
- 被リンク
- 重複コンテンツ
- CMS
- canonical
- URLパラメータ
- URL正規化
- alt属性
- robot.txt
- クリック率
- コンバージョン
- Googleサーチコンソール
- アンカーテキスト
全部みる 閉じる
-
全部みる 閉じる
-
全部みる 閉じる