


検索結果に表示させるためには、まず検索エンジンにWebページを見つけてもらい、インデックスに登録される必要があります。
しかし、すべてのページが自動的に登録されるわけではなく、さまざまな要因で登録されないこともあるのです。
本記事では、インデックスの基本的な仕組みから、登録状況の確認方法、インデックスされない理由と対策について解説します。
SEOの基礎知識 TOPページへSEOにお困りの方へ

本資料はSEOに必要な基本的な知識を理解し、最適な結果を得るために役立つ方法を詳細に説明しています。SEOに関連する問題に直面している方は、無料の相談サービスを利用することで、解決策を見つけることができます。ぜひ、今すぐお申し込みください!
目次
インデックスの役割と重要性
インデックスとは、検索エンジンのクローラーが集めたWebページの情報をデータベースに保存し、検索時に検索結果として表示できるようにすること。
図書館で例えるなら、新しい本が入荷したときに司書が本の内容を確認し、分類番号を振って本棚に配置する作業に似ています。
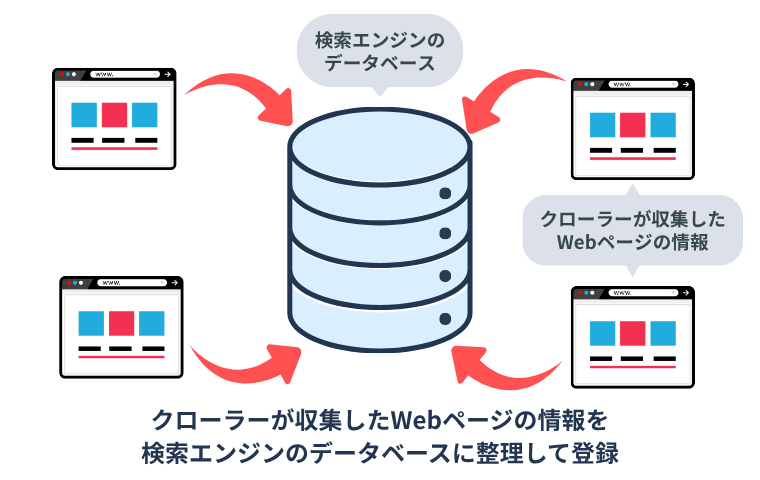
いくら質の高いコンテンツを公開しているWebサイトでも、インデックスされなければ検索ユーザーの目にふれることはありません。
つまり、インデックスに登録されることは検索結果に表示されるための必要条件なのです。
ただし、インデックス登録されたからといって、必ず上位表示されるわけではないことは理解しておきましょう。
検索結果の順位は、ほかのサイトとの比較やコンテンツの評価によって決まります。
<検索結果に表示されるまでのプロセス>
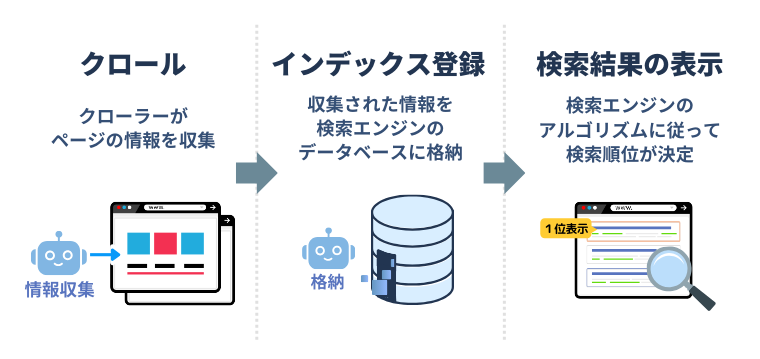
インデックス登録までの流れ
検索エンジンがページを理解してデータベースに登録するまでの流れをより詳細に説明すると、「クロール→レンダリング→インデックス」という3つの段階を踏みます。
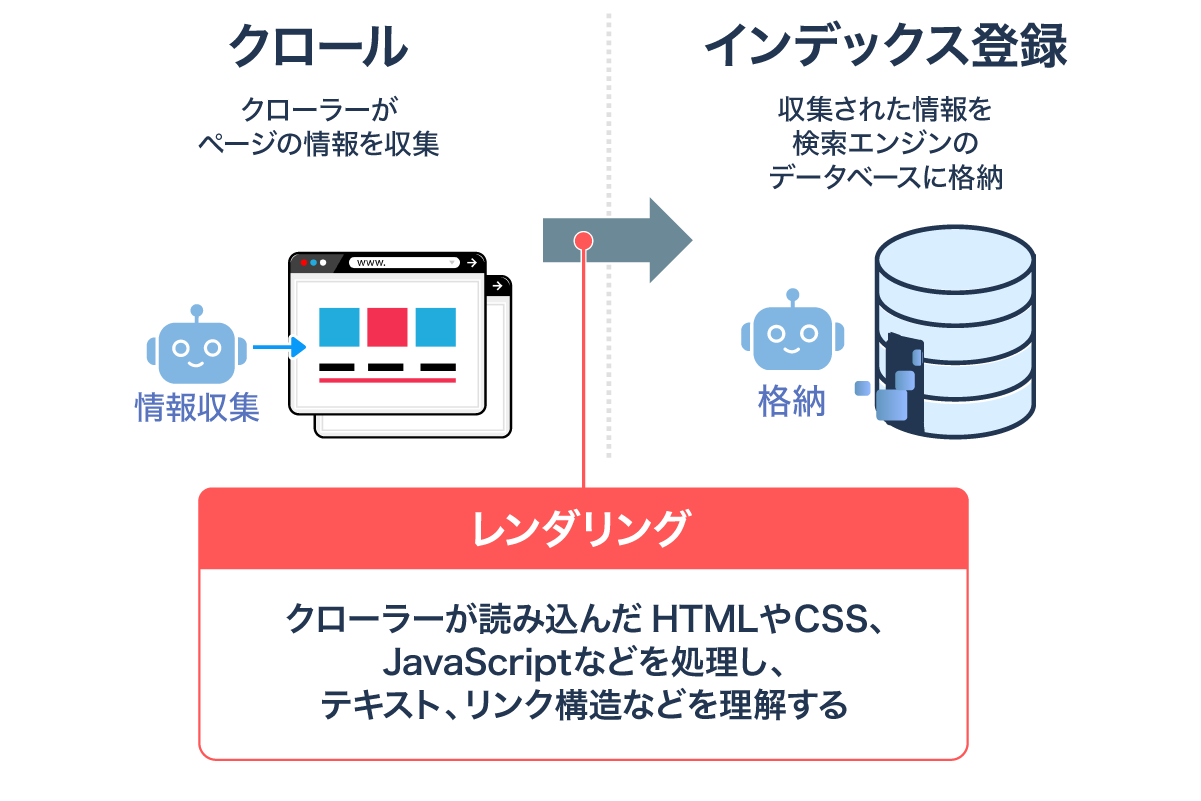
各段階の役割と注意点を下表にまとめました。
<クロール~インデックス登録までの流れ>
| ステップ | 概要 | 注意点 |
|---|---|---|
| ①クロール | クローラーがリンクをたどってWebページを発見・収集する段階。
クローラーが見つけられないページは次の段階に進めない。 |
クローラーに発見されるまでにタイムラグが発生することもある。 |
| ②レンダリング | クローラーがWebページを読み込み、HTMLやCSS、JavaScriptなどを処理して、テキスト、リンク構造などを理解する段階。 | クロールされても、JavaScriptの処理がうまくいかないとレンダリングされない場合がある。 |
| ③インデックス | レンダリング後に整理された情報を検索エンジンのデータベースに保存し、検索結果に表示される対象となる段階。 | ページが高品質かを検証した上でインデックスが決定される。
すべてのページがインデックスされるわけではない。 |
インデックス登録に至らない場合、3段階のうちどこで問題が発生しているかを特定することが重要です。
クロールされているか、レンダリングが適切に行われているかを確認することで、より効果的な対策を立てることができます。
詳しくはこの記事もチェック!


インデックスされているか確認する方法
Webページがインデックスされているかどうかは、簡単に確認することができます。
ただし、ページが公開されてからインデックスされるまでには、多少のタイムラグがあります。
特に新しく作成したページの場合、数日〜数週間かかることもありますので、あらかじめ理解しておきましょう。
<インデックスされているか確認する方法>
Google Search Consoleで確認する
最も正確にインデックス状況を確認できるのが、Google Search Console(GSC)を使う方法です。
<確認手順>
検索窓に確認したいWebページのURLを入力する。
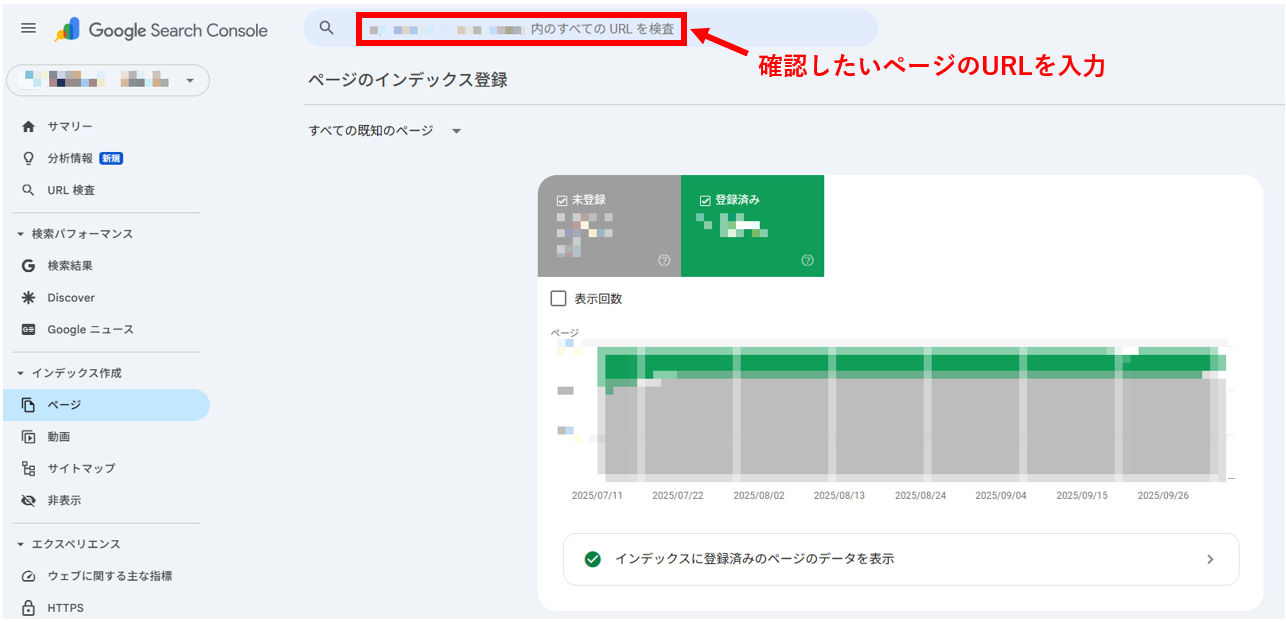
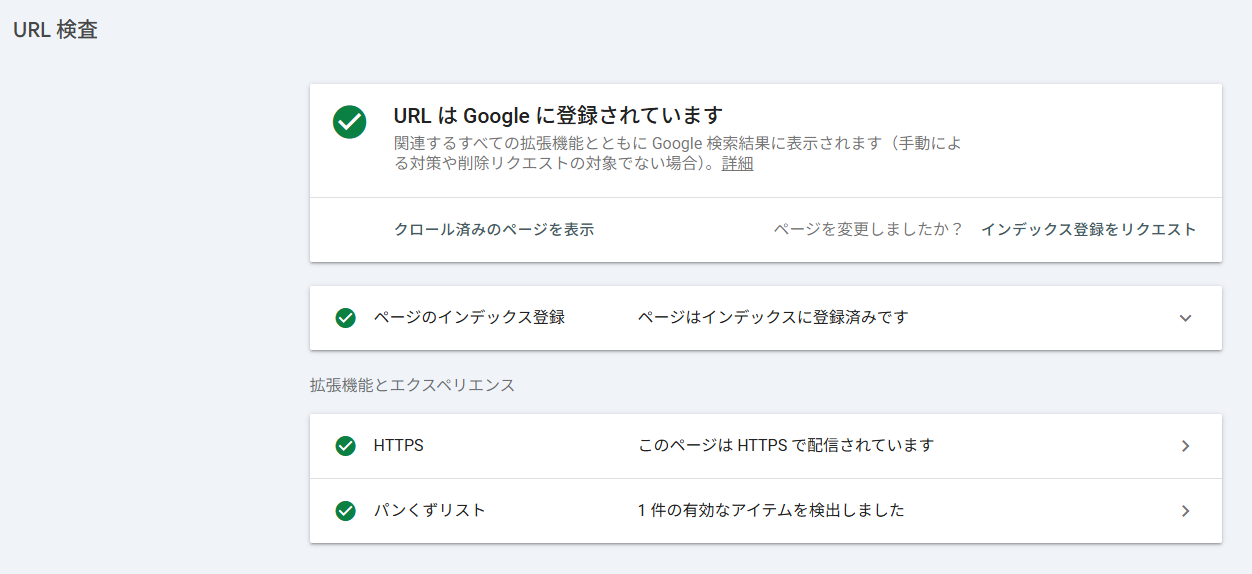
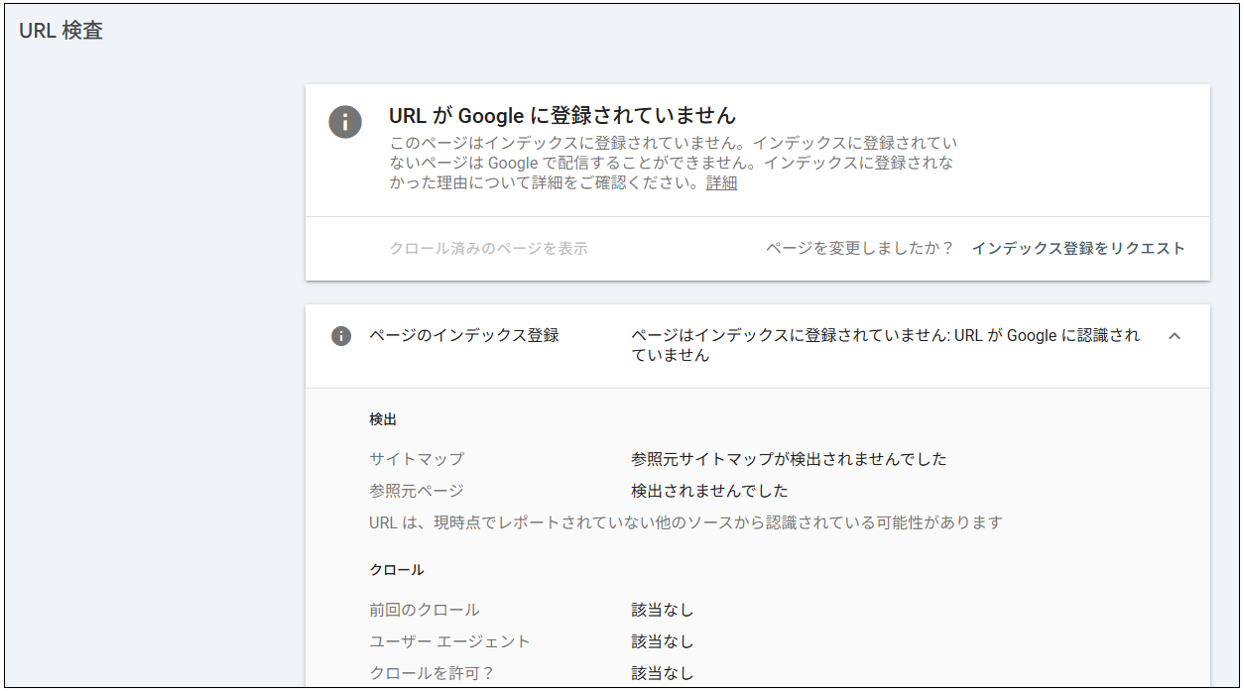
インデックス登録されていると表示される画面。
インデックスされていない場合は、「URLがGoogleに登録されていません」と表示されます。
「site:」検索で確認する方法
Googleの検索窓を使って「site:」検索をする方法もあります。
<確認手順>
Google検索窓に「site:確認したいURL」を入力して検索する。
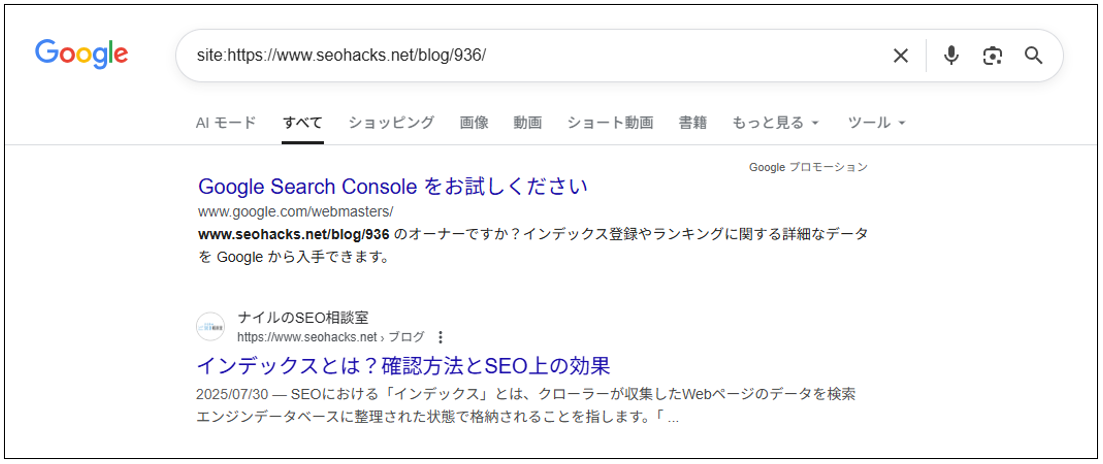
インデックス登録されている場合は、検索結果に表示される。
ただし、「site:」検索はGSCほど詳細な情報は得られません。
そのため、自サイトのページを確認する場合はGSCを活用し、「site:」検索はGSCを見ることができない他社サイトのインデックス状況を見るなど、補助的に使いましょう。
インデックス登録されない理由と対策
ページがインデックス登録されない場合、その背景にはいくつかの理由が考えられます。
ここでは、主な原因と対策を見ていきましょう。
<インデックスされない理由と対策>
noindexタグやrobots.txtでブロックしている
ページがインデックスされない理由として、最初に確認したいのが「意図的なブロック設定」です。
Googleに対して「このページはインデックスしないでください」と指示を出す方法が2つあり、それらが設定されている可能性があります。
ひとつは、ページのHTMLの<head>タグ内にnoindexタグを設定する方法。
もうひとつは、Webサイトのルートディレクトリに配置されているrobots.txtファイルで、特定のページやディレクトリのクロールをブロックする方法です。
これらの設定は、サイト構築時や保守作業中に、テスト環境のページが誤ってインデックスされるのを防ぐなど、適切な用途で活用されます。
しかし、気づかないうちに設定されていたり、テストを経た公開後も削除されないまま残されていたりするケースもあるため、注意が必要です。
<対策>
まず、Google Search Consoleの検索窓に該当のURLを入力し、インデックス状況を確認しましょう。
noindexやrobots.txtでブロックされている場合は、そのように表示されます。
意図的でなければ、これらの設定を削除し、インデックス可能な状態してください。
詳しくはこの記事もチェック!


重複コンテンツが多い
複数のページで同じ内容が存在する重複コンテンツは、検索エンジンがインデックスの判断をする際に問題になることがあります。
例えば、URLパラメータが異なるだけで内容がまったく同じWebページが複数存在する場合、検索エンジンは「どのページをインデックスすべきか」を判断しにくくなり、結果としてインデックスの優先度が下がってしまいます。
あるいは、いずれかのWebページのみインデックス登録され、ほかは除外されることもあります。
<対策>
重複コンテンツの対処法には、2つのアプローチがあります。
ひとつはcanonicalタグを使用する方法。
優先的にインデックスしてほしいWebページにこのタグを設定し、「このページが本家です」と検索エンジンに指示することで、どれをインデックスするかを明確にします。
もうひとつは、適切なURL設計を心がけることです。
構造が明確でシンプルなURL設計を採用することで、そもそも重複が生じにくいサイト構造を実現できます。
詳しくはこの記事もチェック!


ページの品質が低いと判断されている
検索エンジンは単純にWebページの存在を記録するだけでなく、そのWebページがユーザーにとって有用かどうかを判断してからインデックスを決定します。
そこで品質が低いと判断された場合は、インデックス登録されないことがあるのです。
具体的には、ほかのWebページからコピーしたもの、情報が不正確なもの、内容が薄いと判断されたものが該当します。
<対策>
Webページの品質向上を目指すには、オリジナル性の高いコンテンツを作成し、その分野における専門性を高めることが重要です。
Googleが重視するE-E-A-T(経験・専門性・権威性・信頼性)を意識したコンテンツを制作し、検索エンジンからの評価を高めていきましょう。
例えば、実際の経験に基づいた具体的な情報や、専門家による確かな解説をはじめ、検索ユーザーにとって有益な独自情報を盛り込むことが有効です。
詳しくはこの記事もチェック!


技術的な要因
ページの中身や設定に問題がなくても、技術的な要因によってインデックスされない場合があります。
その代表例がページ表示速度の遅さやモバイル非対応です。
検索エンジンはユーザー体験を重視するため、読み込みが遅いページやスマートフォンに対応していないページの評価を下げ、その結果としてインデックスの優先度が低下することがあります。
また、JavaScriptを使用しているページについても注意が必要。
JavaScriptを多用すると、クローラーがうまくレンダリングできず、ページの内容を正しく理解できないことがあります。
その結果、ページ内のテキストやリンク構造が検索エンジンに認識されず、インデックス登録に至らないケースが発生します。
<対策>
ページ表示速度の最適化を通じて、Googleの指標である「コアウェブバイタル」の数値を改善したり、モバイルフレンドリーな設計にしたりすることがまず重要です。
また、JavaScriptの問題についてはさらに踏み込んだ対策が必要。
JavaScriptを多く活用する場合は、SEO上重要なページやJavaScript依存度が高い部分に絞って「サーバーサイドレンダリング(SSR)」(※1)や「プリレンダリング」(※2)を導入するなど、クローラーが正確にコンテンツを認識しやすい環境を整えましょう。
※1 サーバーサイドレンダリング…アクセスごとにサーバーがHTMLを生成して返す方式。
※2 プリレンダリング…事前にHTMLを生成して保存し、アクセス時に返す方式。
参考:JavaScript SEO の基本を理解する - Google 検索セントラル ブログ
詳しくはこの記事もチェック!

効率的なインデックス登録につなげるための土台を整備しよう
インデックスは、検索結果に表示されるための必須条件です。
SEOに取り組むにあたって、もしここに課題がある場合は最優先で取り組む必要があります。
もしインデックスされていない場合は、本記事で解説したとおり、noindexタグやrobots.txtの設定ミス、重複コンテンツなど、さまざまな原因として考えられます。
そのため、どこに問題があるのかを早急に特定し、解決していくことが重要です。
本記事で紹介したポイントを押さえて効率的にインデックス登録されるようにし、SEO施策の成功につなげていきましょう。
SEOの基礎知識 TOPページへSEO対策の悩みをプロに相談してみませんか?

SEOやWebマーケティングの悩みがありましたら、お気軽にナイルの無料相談をご利用ください!資料では、ナイルのSEO支援実績(事例)、コンサルティングの方針や進め方、費用の目安といった情報をご紹介しています。あわせてご覧ください。



編集者
一般情報誌や音楽情報メディアの編集部を経て、2017年にナイルへ入社。コンテンツディレクターとして主に医療系、ライフスタイル系などさまざまなメディアで顧客支援を行う。現在は主に「ナイルのSEO相談室」の制作を担当。
SEO基礎知識 記事一覧
-
- LLMOの効果測定
- LLMO
- AI Overviews
- LLMマーケティング
- ローカルSEO
- Googleコアアップデート
- 構造化データ
- YMYL
- 強調スニペット
- ナレッジパネル
- リッチスニペット
- 内部リンク
全部みる 閉じる

-
全部みる 閉じる
-
- サブドメインとサブディレクトリ
- エンティティ
- コアウェブバイタル
- サイテーション
- SEO記事の作り方
- 検索ボリューム
- ディレクトリ
- リダイレクト
- ペルソナ
- 指名検索
- noindex
- nofollow
- HTTPS
- 被リンク
- 重複コンテンツ
- CMS
- canonical
- URLパラメータ
- URL正規化
- alt属性
- robot.txt
- クリック率
- コンバージョン
- Googleサーチコンソール
- アンカーテキスト
全部みる 閉じる
-
全部みる 閉じる
-
全部みる 閉じる















