SEOやLLMOに関する重要ニュースを厳選してお届けする本シリーズ。
今回は「バックボタンハイジャックがGoogleのスパムポリシーに追加」や「GoogleがクローラーのIPアドレス一覧ファイルのパスを変更」など、Googleのポリシーや技術系の話題をピックアップしました。
いま押さえておきたい最新トレンドを、わかりやすく解説します。
SEOに必要な基礎知識が1冊に!

「SEOを体系的に理解したい」という方に向けて、重要ポイントを1冊に凝縮しました。 SEOの基礎から戦略策定の流れ、具体的な対策方法など、使える情報が満載。 自社だけでのSEOに不安がある場合は、無料相談をご活用ください!
目次
Google、「戻る」ボタンの乗っ取り(バックボタンハイジャック)をスパムポリシーに追加
2026年4月13日(米国時間)、Googleはスパムポリシーを拡大し、ブラウザの「戻る」ボタンを正常に機能させなくする「バックボタンハイジャック」を明確なポリシー違反に追加しました。
この手法が仕込まれたページでは、「戻る」ボタンを押してもすぐに前のページへ戻れず、訪問していない広告ページに飛ばされたり、何度押しても元のページに戻れなかったりといった問題が発生します。
<Chromeの「戻る」ボタン>
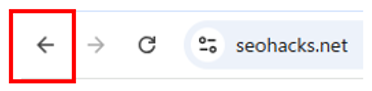
ここをクリックすると通常はすぐに前のページに戻れるが、
バックボタンハイジャックをされていると、クリックしても別の広告ページに飛ばされてしまう。
こうした行為は以前からGoogleの「Google検索の基本事項」で欺瞞的行為として禁止されていましたが、増加傾向にあることを受けて今回改めて明文化されました。
違反した場合は、手動によるスパム対策(検索結果からの除外を含む)やアルゴリズムによる順位低下が適用される可能性があります(施行開始は2026年6月15日から)。
Webサイト運営者が特に注意すべきなのは、自身が意図的に実装していなくても、サードパーティの広告タグや外部スクリプト経由で発生しているケースがある点です。
Google検索から自サイトにアクセスし、「戻る」ボタンで検索結果に戻れるかどうか、実際にブラウザで確認しておきましょう。
このニュースについて、詳しくはこちらをチェック!

<編集部の一言>
「戻る」ボタンをクリックしたのに、見覚えのない広告ページが表示されてしまった――そんな経験がある人も多いのではないでしょうか。Googleはまさにそうしたユーザー体験の阻害を問題視しており、今回のポリシー追加でより明確にNGとした形です。
広告収益のために導入されるケースが多い手法ですが、スパム認定されてしまっては本末転倒!
6月の施行前に自サイトの挙動を確かめ、問題が見つかった場合は開発チームやサイト制作会社と連携して対応を進めましょう。
【クローラーを拒否する可能性も】GoogleがクローラーのIPアドレス一覧ファイルのパスを変更
Googleは自社クローラーが使用するIPアドレスの一覧をJSON形式で公開していますが、このファイルの配置先ディレクトリが変更されました(※)。
- 旧ディレクトリ:developers.google.com/search/apis/ipranges/
- 新ディレクトリ:developers.google.com/crawling/ipranges/
※参照:GoogleクローラーのIP範囲ファイルの新しい場所 - Google Search Centralブログ
Google公式の投稿では、当面は旧パスでも引き続き利用できるとされていますが、4月上旬に旧パスが一時的に利用できなくなるタイミングがありました。
Googleのシステムチェックによるものとのことですが、完全移行までの間に予告なく旧パスが使えなくなる可能性もあります。
特に注意が必要なのは、サーバーやWAF、ファイアウォールなどでGoogleのIPアドレスをホワイトリストに登録して運用しているケースです。
許可するIPアドレスをGoogleのJSONファイルから自動取得している場合、参照先が旧パスのままだとファイルを取得できなくなります。
そうなると、許可リストが更新されず、将来的にGooglebotがサイトをクロールできなくなるリスクがあるでしょう。
該当する場合は、参照先を新ディレクトリに変更してください。
<編集部の一言>
影響を受けるのはIPベースのアクセス制御をしているサイトに限られるため、多くのWebサイトでは特に対応は不要です。ただ、該当する場合に放置すると、ある日突然Googlebotが来なくなる可能性が。
移行期間中の今のうちに、インフラ担当や制作会社に参照先のパスを確認してもらっておきましょう。
Googlebotのクロール上限が「2MB」だった――ドキュメントの記載ミスを修正
Googleがクローラーに関する公式ドキュメントを更新(※)し、Google検索用のGooglebotがHTMLを取得する上限は“2MB”であると明記しました。
参照:Google のクローラーとフェッチャー(ユーザー エージェント)の概要 - Crawling infrastructure
これまで公式ドキュメントには「15MB」と記載されていたため、「制限が厳しくなったのか」と思われそうですが、実際には仕様変更ではなく、以前からの記載ミスが修正されたものです。
つまり、クロール環境が急に変わったわけではありません。
一般的なWebページのHTMLは2MBを大きく下回ることがほとんどで、CSS・JavaScript・画像などは親ページとは別にカウントされます。
これまで問題なくインデックスされていたサイトであれば、基本的に心配は不要です。
ただし、次のようなケースは注意してください。
- インラインのBase64画像
- 巨大なインラインCSS/JavaScript
- 数百項目に及ぶメガメニューなどをHTMLに直接埋め込んでいる
これらに該当する場合は、2MBを超える可能性があります。
Googlebotは2MBに達した時点で取得を止めるため、それ以降にある構造化データやリンクはインデックスされません。
<編集部の一言>
ほとんどのサイトは影響を受けないトピックですが、「15MB→2MB」という数字のインパクトが大きかったためか、SNSなどでも話題になりました。不安な方は、URLを入力するだけでHTMLサイズを確認できる無料ツールもあるので、一度チェックしてみるといいでしょう。
また、重要な構造化データやcanonicalタグはHTMLの前半に配置しておくのが安全です。
SEO・LLMOに困ったら、ナイルにご相談ください
今回は、Googleのポリシー変更や技術的な仕様に関するアップデートをお届けしました。
すぐに対応が必要なものから、知識として押さえておきたいものまで温度感はさまざまですが、いずれもSEO担当者として把握しておきたいトピックです。
自サイトを見直すきっかけとして、ぜひご活用ください。
ナイルではSEO・LLMOに関する最新情報をこちらのページで引き続き発信していきますので、ぜひブックマーク登録をお願いします!
また、自サイトの戦略策定や運営等にお困りであれば、ナイルにお問い合わせください。
SEO・LLMOのプロが親身に対応いたします。
SEO・AI検索対策の悩みをプロに相談してみませんか?

SEOやAI検索対策などWebマーケティングの悩みがありましたら、お気軽にナイルの無料相談をご利用ください!資料では、ナイルのSEO支援実績(事例)、コンサルティングの方針や進め方、費用の目安といった情報をご紹介しています。あわせてご覧ください。


編集者
2007年に創業し、約15年間で累計2,000社以上の会社にマーケティング支援を行う。また、会社としても様々な本を出版しており、業界へのノウハウ浸透に貢献している。(実績・事例はこちら)



関連記事